2025년 기준으로 GPU의 인기가 예전만 못해진 걸까? 아니면 오히려 더 뜨거워졌을까? 미시적·거시적으로 살펴보면, 데이터 센터(DC)나 리테일(RTX) 분야에서는 여전히 높은 수요를 보이고 있는 듯하다. 다만, 이전 세대인 ‘Hopper’ 시리즈에 대한 관심은 다소 줄어든 느낌도 있다. 이런 가운데, 지난주에는 엔비디아의 가장 큰 연례 행사인 GTC 2025가 열렸다. 슈퍼스타 젠슨 황(Jensen Huang)이 역시나 키노트를 맡아 약 2시간 30분 동안 발표를 진행했는데, 그중 인상 깊었던 몇 가지 내용을 소개해보려 한다.
전체 세션이나 기술 항목들은 이미 다양한 블로그나 유튜브 영상에서 잘 정리되어 있으므로, 이 글에서는 중복된 내용을 다루기보다는 핵심적인 몇 가지 포인트만 짚어보려고 한다. 이번 포스팅에서는 그중에서도 특히 Scaling Graph에 대해 자세히 살펴보고자 한다.
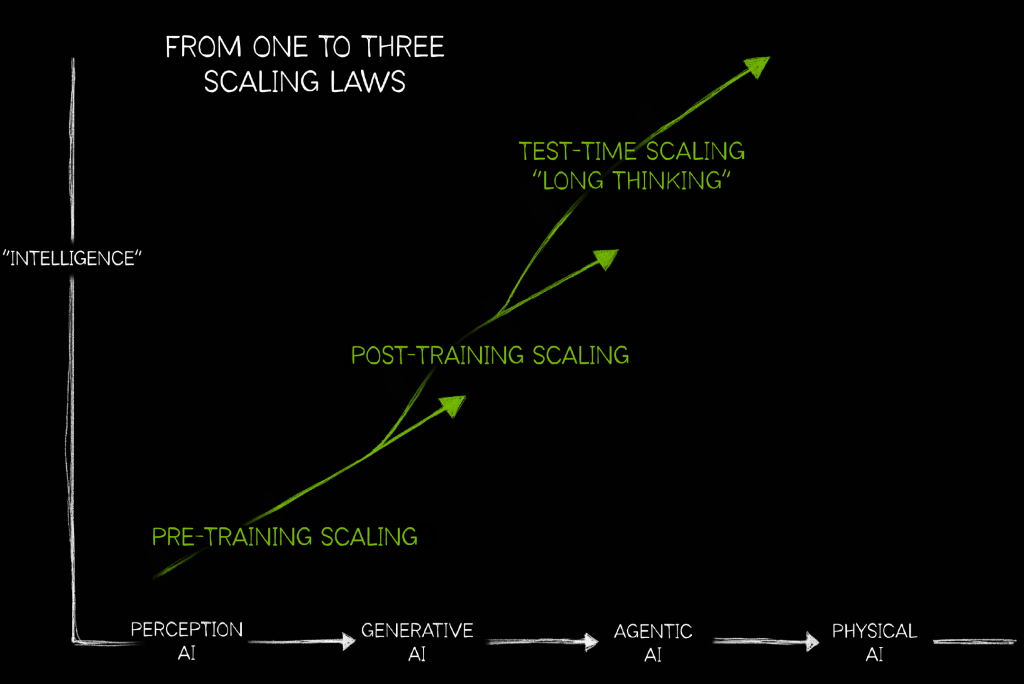
이 그래프는 CES에서도 소개되었던 것이지만, 정확히 언제부터 사용되었는지는 불분명하다. 아무튼 이 그래프를 얼핏 보면, AI가 발전함에 따라 스케일링이 자연스럽게 증가해야 한다는 메시지로 보일 수 있다. 그런데 자세히 들여다보면 다소 독특한 표현들이 눈에 띈다. Pre-training, Post-training, Test-time scaling 같은 용어들이 있고, 그래프 또한 일직선이 아니라, 중간중간 나뭇가지처럼 갈라지거나 삐죽삐죽 튀어나온 형태를 하고 있다. 이 그래프를 시작으로, 뒤에 이어지는 AI Factory 등의 내용은 NVIDIA의 향후 사업 및 제품 전략을 보여주는 핵심적인 단서라고 해도 과언이 아니다.
우선 Y축을 살펴보면 Intelligence으로 표시되어 있다. 이는 AI가 얼마나 ‘똑똑해지는지’를 나타내는 지표로, 정확한 수치를 의미한다기보다는 상대적인 척도로 이해하는 것이 좋다. X축은 AI의 발전 단계를 나타내며, Perception AI→ Generative AI→ Agentic AI→ Physical AI로 구분되어 있다. 이 중 Physical AI은 아직 도래하지 않은 미래 단계이고, Agentic AI는 2025년 현재 우리가 실제로 경험하고 있는 AI의 발전 수준이다.
첫 번째 단계인 Perception AI는 Generative AI 이전의 AI 기술 전반을 의미하는 것이다. 예를 들어, CNN 기반의 컴퓨터 비전, 음성 인식 등 전통적인 AI 기술들이 여기에 포함된다. 그 다음은 모두가 익숙한 Generative AI, 예컨대 ChatGPT, Gemini, LLaMA 등 생성형 AI 모델들이 해당된다. 그리고 Agentic AI는 생성형 AI 또는 LLM을 기반으로 다양한 에이전트를 통해 서비스를 구성하는 방식이다.
즉, 생성형 AI를 바탕으로 실제로 동작하고 판단하는 AI 서비스를 만들려는 다양한 시도들을 포괄한다고 볼 수 있다.
그래프를 보면 Pre-training Scaling, Post-training Scaling, Test-time Scaling “Long Thinking”이라는 용어들이 크게 구분되어 있다. 이러한 기준은 Generative AI 또는 LLM(Large Language Model)을 중심으로 구성된 개념이라고 이해하면 훨씬 빠르고 자연스럽다. 우선 LLM을 학습시키고 실제로 활용하기 위해서는 크게 두 가지 학습 단계를 거친다. 첫 번째는 트랜스 포머 아키텍처를 기반으로 하는 Pre-training 단계다. 이 과정에서는 매우 광범위한 범주의 데이터를 활용해 모델을 사전 학습시키며, 엄청난 양의 토큰과 지표 데이터가 투입된다는 점은 잘 알려져 있다. 이렇게 Pre-trained 모델이 완성되면, 이를 기반으로 Fine-tuning, 도메인 특화 학습, 또는 Prompt 기반의 추가 학습이 이뤄진다. 이후 단계가 바로 Post-training이라 할 수 있다.
세 번째 단계인 Test-time Scaling “Long Thinking”은 흔히 말하는 Runtime Inference 과정, 즉 실시간 추론 시점에서 발생하는 모든 연산 흐름을 의미한다. 이 부분은 단순히 모델을 학습시키는 과정이 아닌, 모델이 실제로 서비스를 제공하는 시점의 복잡한 처리 단계에 해당한다. 예를 들어, RAG(Retrieval-Augmented Generation) 같은 경우를 생각해보면 이해가 쉽다. RAG에서는 LLM이 제한된 서치 스페이스(search space) 안에서 답변을 하도록 구성해준다. 이때 검색된 데이터는 LLM이 이해할 수 있는 형태인 임베딩된 토큰으로 변환되어 모델에 입력된다. 이러한 방식이 잘 동작하려면, 당연히 LLM 자체가 고도화되어 있어야 하고, RAG가 참조하는 데이터셋도 정확하고, 도메인에 특화되어 있으며, 충분한 양이 필요하다. 또한, LLM의 1차 응답 이후, 그 결과를 후처리(post-processing)하거나 다른 LLM에 다시 입력해 추가 reasoning을 유도하는 구조도 자주 등장한다. 이처럼 하나의 응답 결과를 다시 토큰화하여 다른 모델에 넘기고, 이 과정을 여러 차례 반복하는 흐름이 Test-time Scaling의 핵심이다. 특히 Chain-of-Thought(연쇄적 사고)와 같이 reasoning이 여러 단계를 거치는 경우, 이러한 토큰 생성 → 모델 입력 → 응답 생성의 사이클이 매우 빠르게 반복된다.
따라서 이 단계에서는 토큰화 속도, 통신 지연, 처리 속도 최적화 등이 중요한 이슈가 된다. 이 전체 과정을 통틀어 Test-time Scaling 혹은 Long Thinking이라고 부른다. 단순한 정답 생성이 아니라, 모델이 고차원적 추론을 반복 수행하는 실제 상황을 가리킨다.
따라서 그래프에 등장하는 용어들을 다음과 같이 대응시켜 이해할 수 있다:
- Pre-training Scaling → 사전 학습 과정의 확장
- Post-training Scaling → 후속 학습(Fine-tuning 등)의 확장
- Test-time Scaling “Long Thinking” → 실제 추론 시점에서의 처리 확장
물론 이 그래프에 대한 상세한 공식 분석 자료나 테크니컬 문서는 아직 부족한 상태라는 것을 감안하고 봐주기 바란다.
여기까지 설명을 들은 사람중 눈치가 빠른 사람이라면 아마도 그래프의 구조를 어느 정도 이해했을 것이다. 그래프에서 나뭇가지처럼 갈라지는 형태는 기존 컴퓨팅 스케일링 패러다임이 유지되는 상태에서, 새로운 형태의 컴퓨팅 스케일이 추가되고 있다는 의미로 해석할 수 있다. LLM 이전의 시기에는 Pre-training이라는 개념 자체가 거의 존재하지 않았기 때문에, 이 단계는 LLM이나 유사한 대규모 모델에서 주로 나타나는 특징이다. 따라서 Pre-training은 전통적인 모델에는 적용되지 않을 수도 있지만, 이 그래프에서는 하나의 일반적인 학습 흐름으로 확장해 표현한 것으로 보인다. 비유하자면, Perception AI 단계에서는 대부분의 컴퓨팅 리소스가 Pre-training 과정에 집중되어 있었다는 것이다. 하지만 Generative AI 시점으로 넘어오면서부터는 Pre-training뿐 아니라 Post-training의 중요성도 커지기 시작했고, 이에 따라 컴퓨팅 자원의 활용 방식에도 새로운 패러다임이 등장했다. 그리고 이 두 단계가 결합되어 AI의 지능, 즉 Intelligence가 향상되는 흐름을 만든다. 여기에 RAG 같은 기법이 도입되고, AI가 Agent 형태로 진화하면서 Post-training 외에도 Chain of Thought와 같은 고차원적인 추론 단계들이 더해진다. 이러한 환경에서는 Test-time scaling의 중요성이 더욱 커진다.
결국 Pre-training, Post-training, 그리고 Test-time scaling이라는 세 가지 스케일링 방식이 유기적으로 결합될 때, 인공지능의 전반적인 Intelligence가 더욱 높아질 수 있다는 메시지를 이 그래프는 담고 있는 것이다.
그래프에서는 각 패러다임의 Scaling 이 마치 화살표로 끝나는 것처럼 보이지만, 실제로는 Scaling 이 거기서 멈추거나 사라진다는 의미는 아니다. 계속해서 이어지는 흐름이지만, 시각적으로 복잡해지는 것을 피하기 위해 화살표로 표현을 끊은 것으로 보인다.
그래서 이 부분은 단절이 아닌 표현상의 단순화라고 이해하는 것이 적절하다. 만약 이를 단순히 화살표가 끝났다고 해석하면, 이전 패러다임의 컴퓨팅 Scaling 이 더 이상 존재하지 않는 것으로 오해할 수도 있기 때문에 주의가 필요하다.
이 그래프를 설명하면서 젠슨 황은 이러한 스케일링을 달성하기 위한 몇 가지 구체적인 방법도 함께 소개했다. 그 중 첫 번째는 Tensor Parallelism, 두 번째는 Pipeline Parallelism, 그리고 세 번째는 Expert Parallelism이다. Tensor Parallelism은 하나의 텐서를 여러 장비에 나누어 분산시키는 방식으로, 주로 대규모 행렬 연산에서 사용된다. Pipeline Parallelism은 학습 또는 추론 과정을 여러 단계로 나눈 후, 이 단계들을 병렬적으로 처리하도록 파이프라인 구조로 운영하는 방식이다. 즉, 하나의 연산 흐름을 여러 처리 유닛이 순차적으로 맡아서 처리하되, 전체적으로는 병렬로 동작하게 만든다. 세 번째인 Expert Parallelism은 MoE(Mixture of Experts) 같은 기법을 의미한다. 여러 개의 전문가 모델, 즉 Expert들을 구성한 뒤, 입력에 따라 각 Expert가 선택적으로 활성화되어 작업을 수행하도록 하는 방식이다. 이는 계산 효율을 높이고, 모델의 표현력을 확장하는 데 효과적이다.
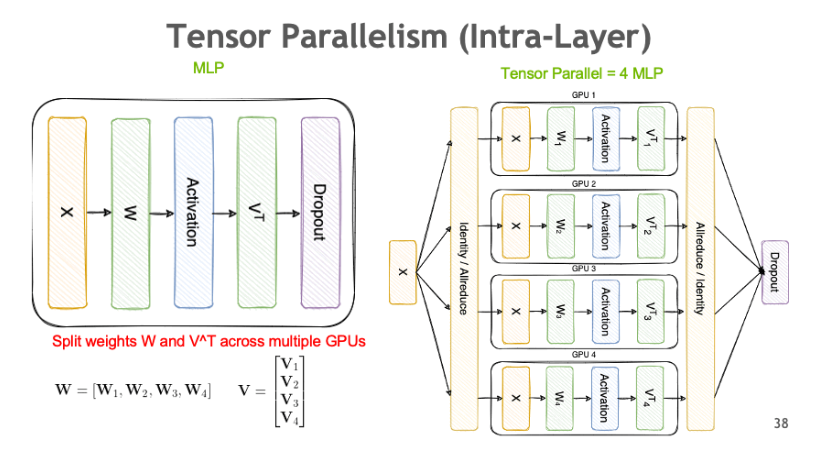
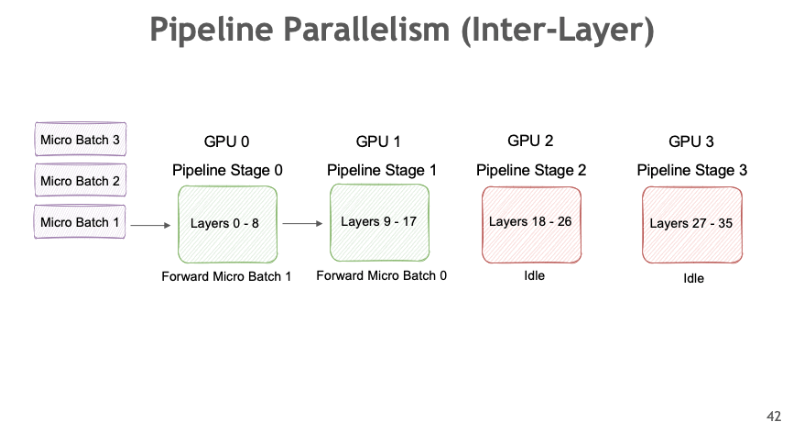
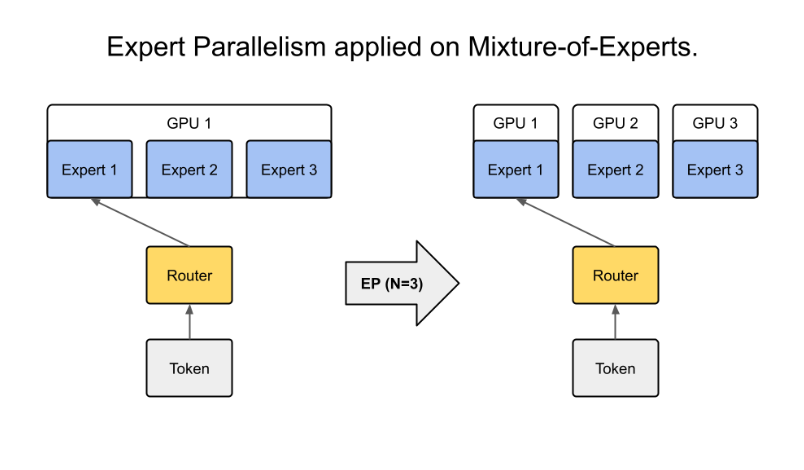
(그림 출처: NVIDIA NeMo Framework User Guide – https://docs.nvidia.com/nemo-framework/user-guide/latest/nemotoolkit/features/parallelisms.html)
이 세 가지 병렬화 방식은 반드시 기억해두어야 한다. 그 이유는 다음 원포인트 레슨에서 소개할 NVIDIA의 Dynamo이 이 세 가지 병렬화를 효과적으로 활용해 전체적인 reasoning 성능을 비약적으로 끌어올렸기 때문이다. 실제로 해당 그래프 설명 세션에서도 언급되었지만, NVIDIA는 이 병렬화 기법들을 조합하면서 옵션을 켜고 끄는 방식으로 다양한 설정을 테스트하고, 그 결과 가장 최적화된 Reasoning 성능을 확보할 수 있는 조합을 내부적으로 찾아낸 것으로 보인다.
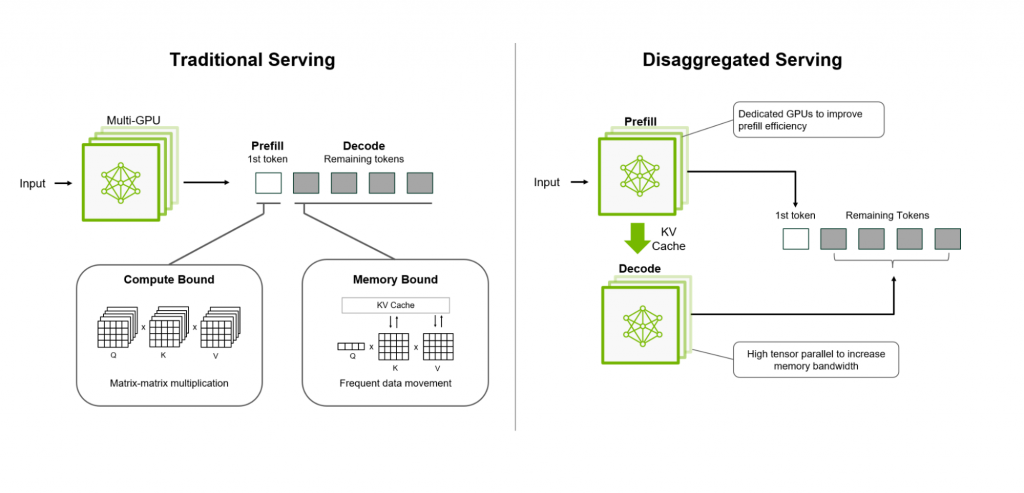
다음 원포인트 레슨으로는 NVIDIA의 Dynamo에 대해서 Keynote의 설명을 조금 자세히 소개 하도록 하겠다. Dynamo는 코드 분석 등으로 별도의 깊이 있는 시리즈로 소개 하도록 하겠다.