이번 포스팅에서는 GTC 2025 키노트 발표 내용 중 Hopper의 성능 향상을 설명하는 그래프를 해석해 보자. 젠슨 황이 발표 중에 “우리는 수학적인 표현을 대중적인 스피치에서 전달하는 몇 안 되는 회사다”라고 말하기도 했다. 농담처럼 들리지만, 실제로 해당 그래프를 제대로 이해하려면 상당한 수준의 배경 지식이 필요하다. 이번 글에서는 그 그래프가 담고 있는 핵심적인 의미를 알아보자. 우선 그 문제(?)의 그래프를 살펴 보자.
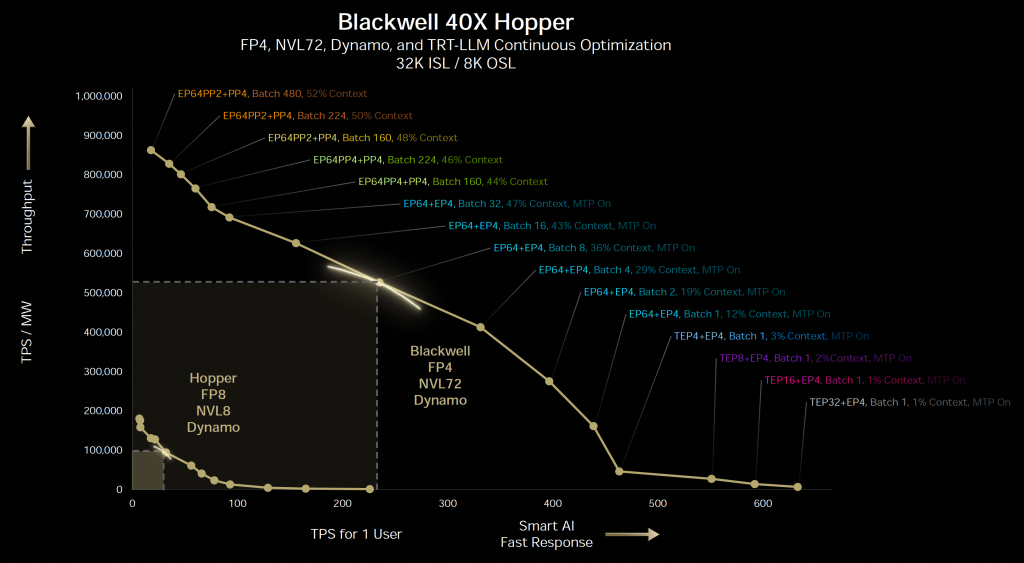
시작부터 어질 어질 하다. 우선 X축을 살펴보면, 이는 실제 AI 서비스를 제공할 때 사용자가 얼마나 빠르게 토큰 응답을 받을 수 있는지를 나타내는 지표이다. 이 값은 당연히 높을수록 좋지만, 그에 따른 반대 급부가 존재한다. 바로 Y축이다. Y축은 단위 전력당 생성할 수 있는 토큰 수, 즉 동일한 전력 소비 하에서 얼마나 많은 TPS(Tokens per Sencond) / MW(Mega Watt)를 낼 수 있는가를 의미한다. 응답 속도를 빠르게 하려면 더 많은 연산을 수행해야 하므로, 필연적으로 전력 소모가 증가하게 된다. 그렇게 되면 분모가 커지고, 결과적으로 전력 대비 토큰 수는 줄어들게 된다.
이것이 이 그래프의 기본적인 형상이다. 그래프의 목적은 간단하다. 개인 사용자에게 빠르게 응답하는 속도(X축)와, 시스템 전체가 전력 효율적으로 얼마나 많은 토큰을 생산하는지(Y축) 이 두 가지를 동시에 고려하는 것이다. 그리고 이 두 지표가 만나는 그래프 상의 한 지점에서, X와 Y가 만들어내는 면적이 가장 넓어지는, 즉 최적화된 균형점(Optimal Point)을 찾는 데에 이 그래프가 사용된다. 젠슨 황이 말한 “수학적인 개념”이 바로 이 지점에 해당한다. 그리고 이 최적 조합을 찾아내기 위해 활용된 것이 바로 NVIDIA Dynamo이다. 그래프에서 확인할 수 있듯이, Hopper Architecture, Blackwell architecture 모두 NVIDIA Dynamo를 기반으로 한 최적화가 적용된 모습을 보여준다.
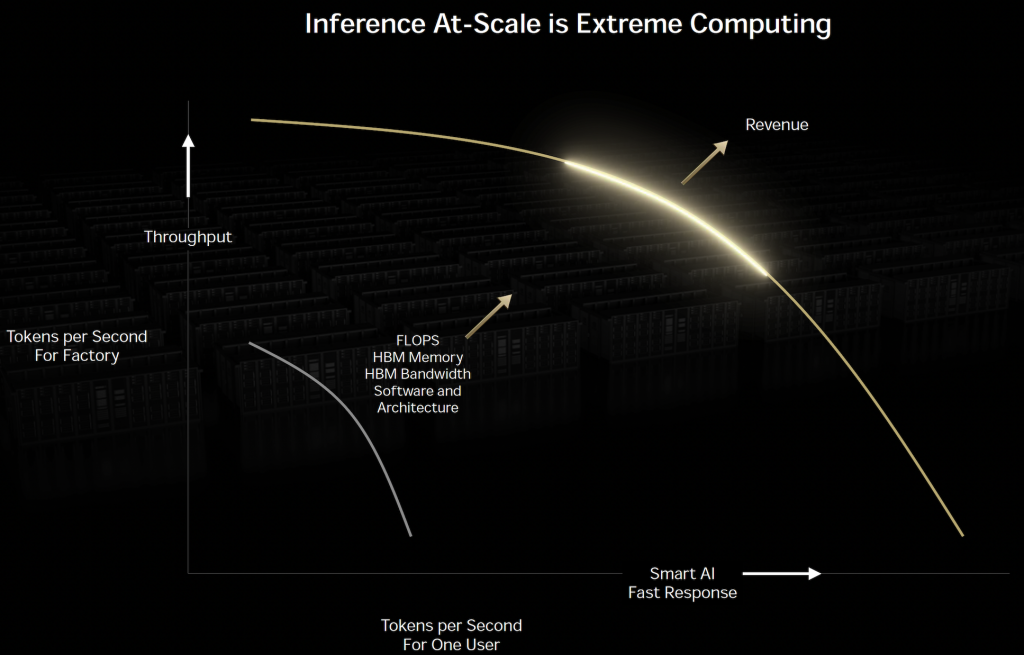
그렇다면 Hopper architecture에서 Blackwell architecture로 발전하면서 그래프가 우상향 방향으로 이동할 수 있었던 이유는 무엇일까. 이 질문에 대한 힌트는 앞서 소개한 Inference Scale 그래프에서 찾을 수 있다. 아래 그림을 보면 X축과 Y축은 동일하게 구성되어 있으며, 그래프의 궤적이 아래에서 위로 우상향으로 이동한 원인을 몇 가지 항목으로 설명하고 있다. FLOPS의 증가, HBM 메모리 대역폭 향상, 그리고 Software와 Architecture의 변화가 그것이다. 이 중 소프트웨어는 NVIDIA Dynamo를 의미하는 것으로 보이고, architecture는 세대별 GPU 구조인 Hopper, Grace Blackwell을 지칭하는 것으로 해석된다. 성능 향상은 언제나 여러 요인이 복합적으로 작용한 결과이지만, 이번 경우는 특히 더 복잡하게 얽혀 있는 구조를 보인다. 따라서 Hopper와 Blackwell의 차이를 이해하는 것만으로는 부족하며, 이들이 NVL8, MVL72와 같은 단일 랙 단위 시스템으로 어떻게 확장되었는지도 함께 고려해야 한다. 다만 현재 시점에서는 Blackwell Architecture의 White paper가 Grace Blackwell Architecture로 통합되어 설명되고 있어, Blackwell 단독 Architecture의 성능을 분리해 Hopper Architecture와 1대 1로 대응해서 검토하기는 어렵다. 간접적으로 RTX 계열 Blackwell Architecture를 통해 유추할 수도 있지만, 데이터센터용 Architecture와 컨슈머용 Architecture는 목적과 구조가 다르기 때문에 정확한 비교는 어렵다. (이 부분은 작가 본인의 정보가 부족할 수 있으니 감안하고 읽어 주길 바람) 또한, GTC Keynote에서 발표된 그래프에 표시된 Hopper가 Grace Hopper를 의미하는 것인지, Hopper를 뜻하는 것인지 명확하지 않아 비교 지점 자체도 다소 애매한 측면이 있다.
이러한 이유로, 공정한 비교를 위해 Grace Hopper와 Grace Blackwell, 특히 NVL을 통해서 랙 단위로 구축된 환경 기준에서 분석하였다. 참고로 Cerebras에서는 이러한 구성을 appliance mode라고 부르지만, NVIDIA는 이에 대한 명확한 명칭을 사용하지 않는다. 따라서 이 글에서는 편의상 해당 구성을 단일 랙 시스템, 또는 랙 단위 서버 비교라는 임의의 표현으로 사용하고자 한다.
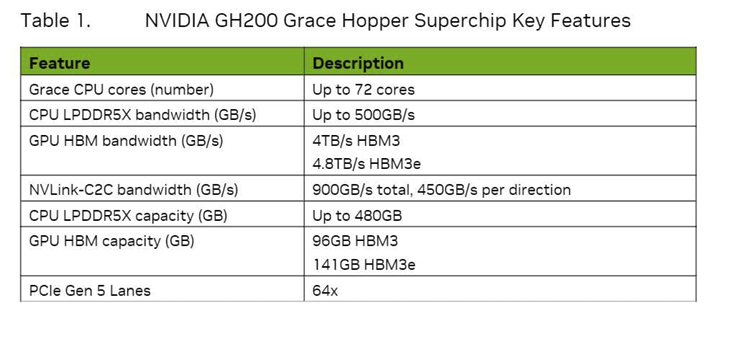
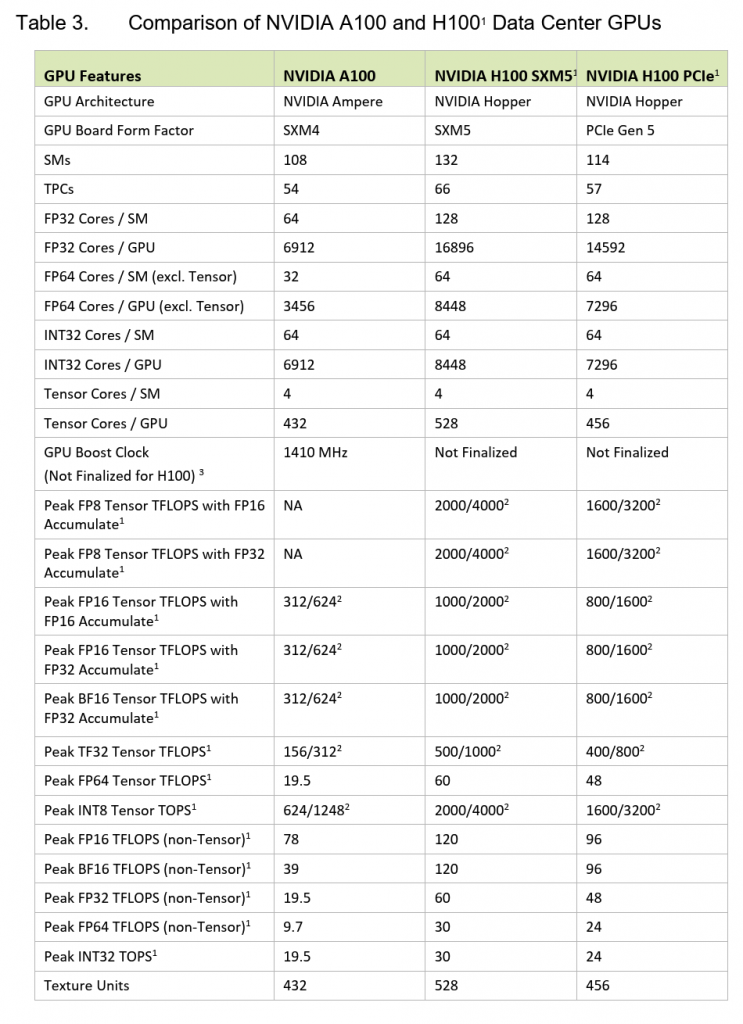
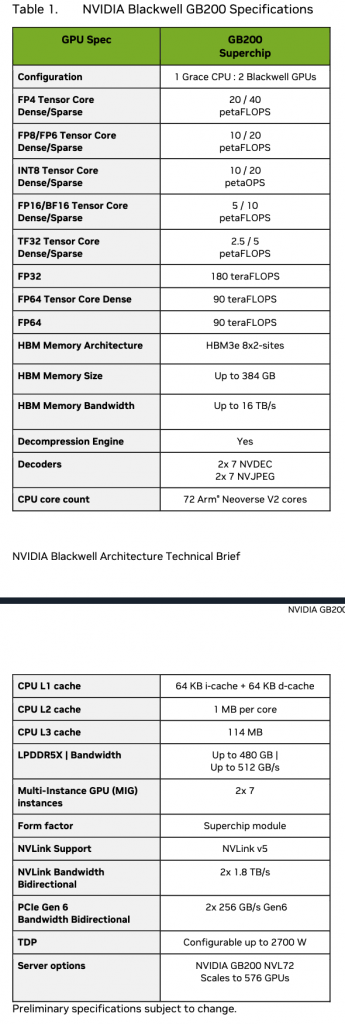
스펙 문서를 읽다 보면 내용이 방대하고 복잡해서 쉽게 피로감을 느끼게 된다. 모든 항목을 다 확인할 필요는 없기 때문에, 이번에는 왼쪽에 있는 Table 3번과 오른쪽에 있는 Table 1번에 집중해 보고자 한다. 두 표는 서로 다른 white paper에서 가져온 자료이므로, 내용을 해석할 때 출처를 명확히 구분할 필요가 있다. 가장 큰 차이점 중 하나는 Blackwell Architecture와 Hopper Architecture가 지원하는 데이터 타입이 다르다는 점이다. Blackwell은 FP4를 포함한 FP4, FP8, FP16까지 폭넓은 실수 연산 타입을 지원하지만, Hopper는 FP16까지만 지원한다. 즉 Hopper는 단정밀도(Single Precision) 이하의 연산을 하드웨어 수준에서 직접 처리하지 않는다는 것을 의미한다. Hopper Architecture에서는 FP8이나 FP16 연산을 하려면, 기존 FP32 연산 유닛을 쪼개어 에뮬레이션 방식으로 처리해야 하므로, 연산 자체는 가능하지만 성능 측면에서는 불리하다. 하드웨어적으로 직접 지원하지 않기 때문에, 연산 속도가 느릴 수밖에 없다.
이러한 차이는 white paper의 예시를 통해서도 확인할 수 있다. 예를 들어, FP8을 FP16 코어로 누적(accumulation) 연산할 때의 성능 수치를 보면, Hopper는 ALU 기반 처리로 인해 효율이 떨어지는 반면, Blackwell은 Tensor Core 수준에서 직접 연산을 처리할 수 있어 훨씬 빠른 성능을 낼 수 있다. 정밀도 수준에 따라 FP16, FP32, FP64 연산이 어디서 처리되는지도 중요한 차이점이다. Hopper에서는 이들 연산이 모두 일반적인 ALU에서 수행되지만, Blackwell에서는 Tensor Core에서 직접 처리되도록 설계되어 있다. 이는 곧 범용 AI 연산뿐 아니라 고정밀 수치 계산까지도 Tensor Core를 통해 가속할 수 있다는 뜻이다. Blackwell은 Tensor Core에서 Dense Matrix와 Sparse Matrix를 작은 실수형 데이터에서도 모두 지원하는데, 특히 Sparse Matrix를 하드웨어 레벨에서 처리한다는 점이 주목할 만하다. 이 기능은 대규모 모델에서 빈도가 낮은 가중치를 효율적으로 스킵할 수 있어, 연산 효율을 획기적으로 개선할 수 있는 중요한 요소가 된다.
또한 Blackwell은 8비트 정수(INT8)도 지원하는데, 이는 해당 데이터 타입을 처리할 수 있는 전용 산술 장치(ALU)가 탑재되어 있음을 뜻한다. 이러한 하드웨어적 지원은 모델 양자화(quantization)에 유리하며, 더 작은 데이터 단위를 빠르게 처리할 수 있어 추론 속도 향상에 기여한다.
White Paper는 다양한 정보가 혼합되어 있으니 몇가지만 추려서 확인해 보도록 하자.
| 비교 항목 | Grace Hopper | Grace Blackwell | |
| FP8 / FP4 연산 | 4 PFLOPs (FP16으로 연산, 2개 Hopper 합산) | 40 PFLOPs (2개 Blackwell 합산) | 10배 |
| HBM Bandwith | 4.8 TB/s | 16 TB/s | 약 4배 |
| NVLink Bandwidth | 900 GB/s | 3.6 TB/s | 4배 |
개선된 항목들의 효과의 조합으로 그래프의 위치가 우상향이 되어 우상단의 그래프가 그려질 것이다. 이는 아에 Scale 커지고 처음에 말한 Dynamo로 선분위를 탐색하면서 X축 * Y축의 넓이가 가장 큰 점을 탐색 하는 것이다. 그래프에 표시해서 보면 아래와 같다.
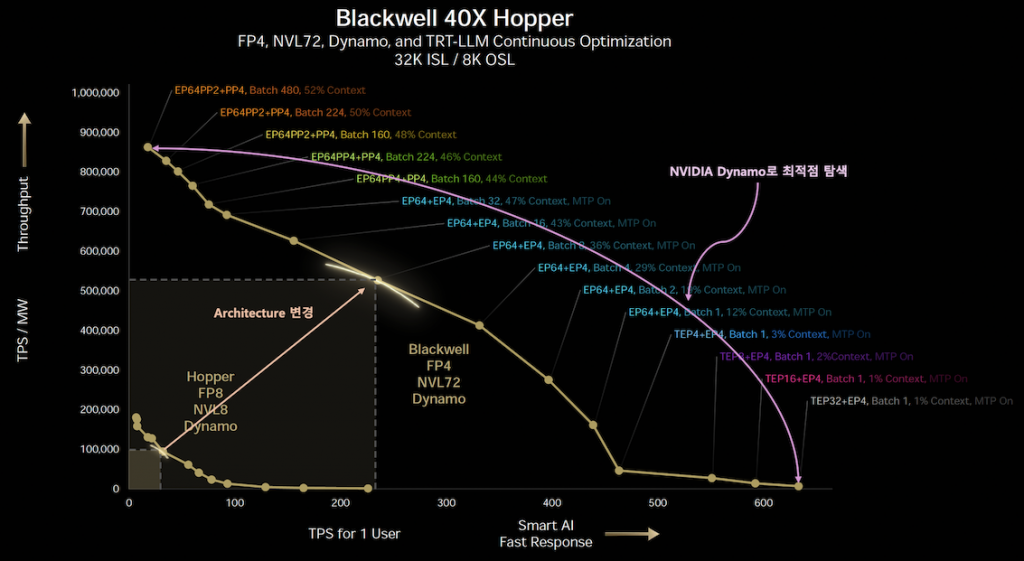
여기까지 정보를 잘 소화했다면 그래프의 구조와 Performance Jumping Gap의 구조를 이해할 수 있을 것 같다. 이제 마지막으로 NVIDIA Dynamo와 최적점 탐색에서 나오는 수 많은 조합의 의미를 알아 보고 긴 글을 마무리 하도록 하겠다. 우선 NVIDIA Dynamo를 설명한 Keynote 슬라이드를 살펴 보자
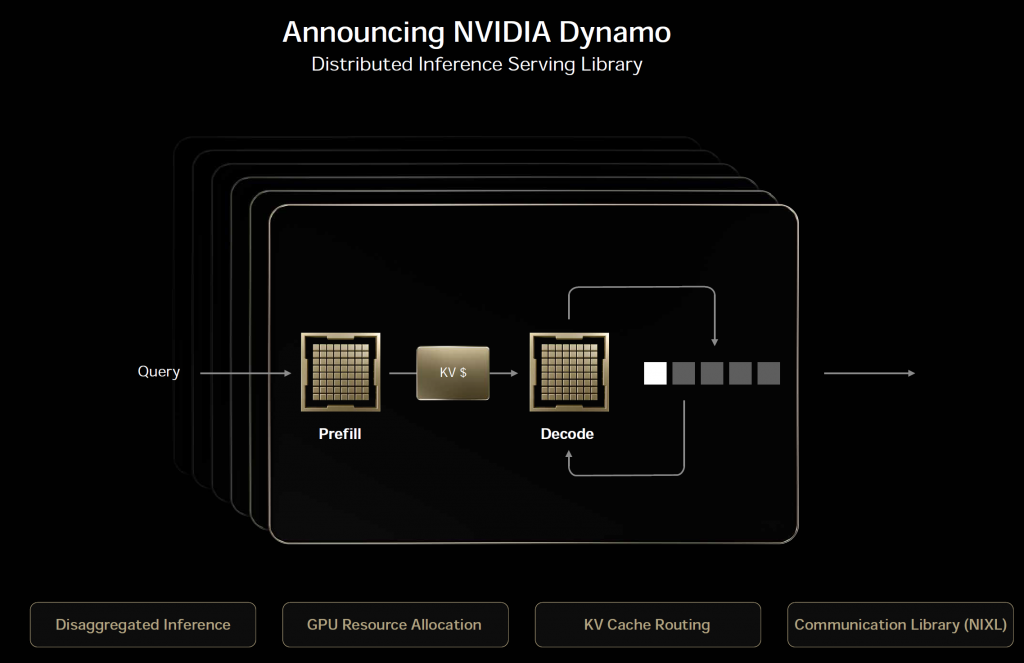
NVIDIA Dynamo는 별도의 포스팅에서 조금 자세히 다루도록 하고 여기서는 개념만 소개 하도록 하겠다. NVIDIA Dynamo는 LLM Model과 Data Center GPU Architecture에 독립적인 Software Framework이다. 아래 내용은 Github의 NVIDIA Dynamo Repository의 Document(https://github.com/ai-dynamo/dynamo/blob/main/docs/architecture.md)의 일부 분이다. 그렇다! 오픈 소스인것이다!
- Disaggregated prefill & decode inference : KV Cache 앞뒤 Pipe를 분리하여 GPU가 많이 필요로 하는 Decode Pipe에 GPU 사용률을 높이고 Pipeline 효과를 높였다.
- Dynamic GPU scheduling : GPU를 Model 별로 정적으로 할당하지 않고 GPU Pool 처럼 운영하여 필요한 리소스에게 할당했다.
- KV cache offloading : KV cache를 Tiering 하여 효과적으로 Cache를 운영하면서, Cache의 운용 용량을 향상하였다.
- Accelerated data transfer : NIXL을 사용하여 네트워크 성능을 높여 전체적인 속도를 향상 하였다.
NIXL은 NVIDIA Inference Xfer Library의 약자로 Point to point 통신의 성능을 높인 라이브러로 역시 GitHub에 공개되어 있다. 우선 개념적인 부분만 알고 넘어가고 자세한 내용은 다음 포스트에서 확인해 보도록 하자.
마지막으로 NVIDIA Dynamo에서 최적화 점을 찾기 위해서 사용한 조합에서 사용된 약어들의 의미를 정리해 두었다. 아래 표에 있는 내용을 보고 약자의 의미를 확인하길 바란다.
| 약어 | 원 용어 또는 의미 |
| ISL / OSL | Input Sequence Length / Output Sequence Length |
| FP4 | 정밀도4비트 부동 소수점 |
| NVL72 | 72개의 GPU가 NVLink로 연결된 단일 랙 시스템 |
| TRT-LLM | TensorRT-LLM |
| EP | Expert Parallelism — MoE의 expert들을 여러 GPU에 분산 |
| PP | Pipeline Parallelism — 모델 레이어를 여러 GPU에 순차 분산 |
| TEP | Tensor Parallelism — 텐서 병렬 |
| Batch | 한 번에 처리하는 요청 수 |
| Context % | 토큰 중 과거 컨텍스트 비율 (높을수록 긴 히스토리, 낮을수록 실시간) |
| MPT | Multi-Tensor Parallelism |
각 용어에 대한 상세한 설명이나 의미까지 설명하기에는 포스팅이 기어지니 NVIDIA Dynamo 설명 포스팅에서 상세 내용은 확인해 보길 바라며 이면 포스팅을 마치도록 하겠다.