그 설정, 다른 모델에서도 통한다. 거의.
전편에서 정리한 suffix 구성을 10개 모델 × 7개 실측 corpus × 6개 측정점 — B200×8 위 406셀(420셀 중 96.7%)로 재검증한 기록. 그리고 vLLM 기본 설정의 처리량을 +36% 흔든 새 변수 하나, 호스트 DSA.
전편의 결론은 단순했다. 코드 한 줄 고치지 않고 vLLM 내장 설정 — speculative_config의 suffix decoding,
적절한 cudagraph mode — 만으로 Llama-3.3-70B를 모든 워크로드에서 가속할 수 있다는 것.
하지만 그건 모델 하나, 하드웨어 하나에서의 결론이었다. 이번에는 질문을 뒤집었다.
같은 처방이 7B부터 671B MoE까지, 10개 모델에서도 살아남는가?
B200×8에서 10개 모델 × 7개 corpus × 6개 측정점, 406셀을 채워 답했다.
결과를 먼저 말하면 — suffix는 70셀 중 36셀에서 이겼고, 두 개의 분명한 예외를 만났다.
그리고 측정 도중, 설정과 무관하게 vLLM 기본 설정의 throughput을 +33~36% 흔드는 호스트 변수를 하나 발견했다.
전체 결과부터
10개 모델 × 7개 corpus × 6개 측정점, 70셀 전부.
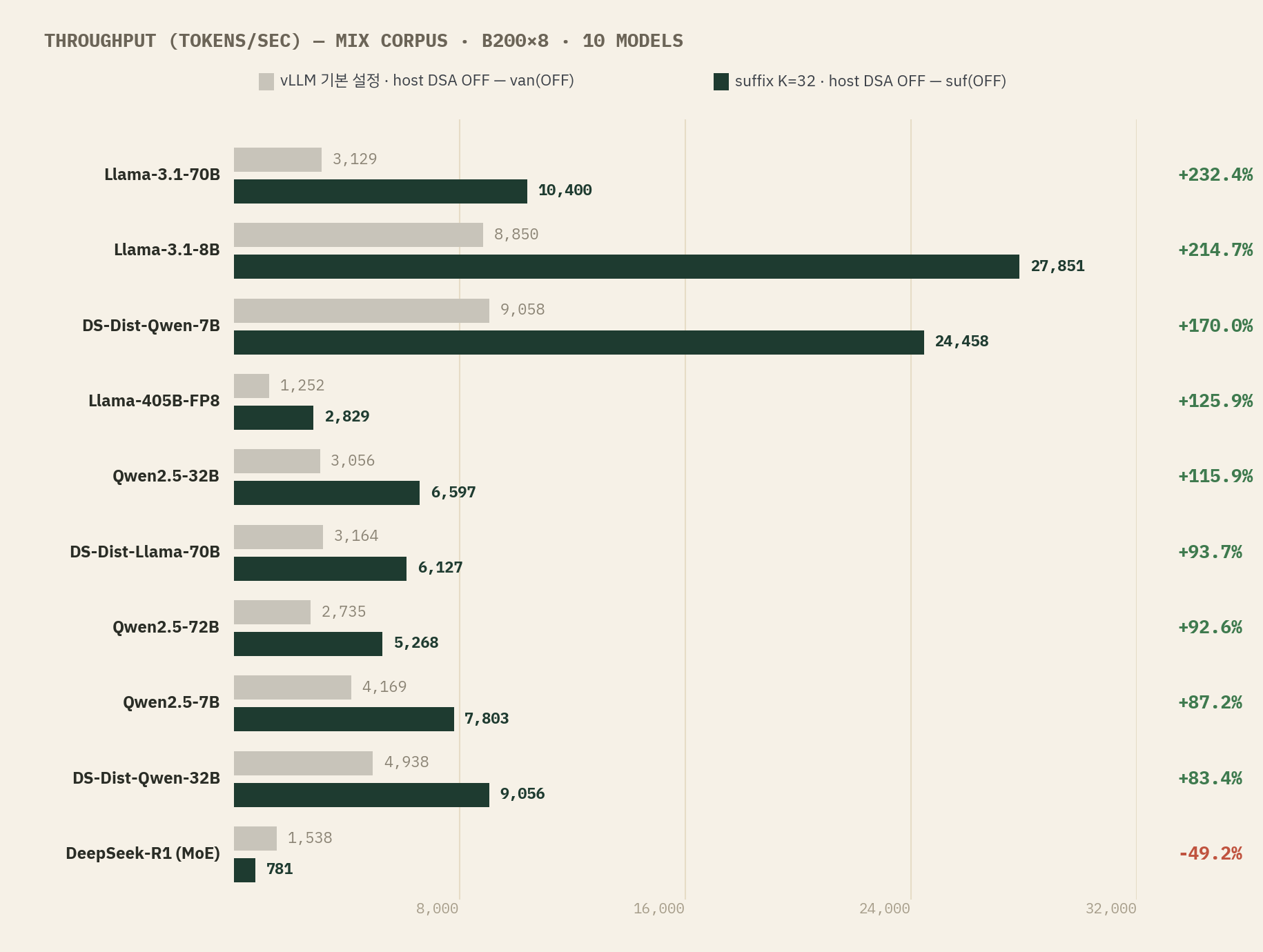
같은 GPU, 같은 harness, 같은 real-trace prompt다. 먼저 운영 분포 proxy인 mix corpus에서 vLLM 기본 설정 그대로인 van(OFF)와 suffix decoding을 켠 suf(OFF)를 비교하면 이렇다. 라벨 괄호 안의 OFF/ON은 vLLM 설정이 아니라 호스트 DSA의 상태다 — 여기서는 둘 다 호스트 DSA OFF로 맞춘 동일 조건 비교이고, 자세한 정의는 §02에 있다.
그리고 아래가 70셀 전체다. 각 측정 조건의 자세한 정의는 §02에 있고 — 짧게는 호스트 DSA OFF/ON × vLLM 기본 설정(van) / suffix(suf) / vllm-DSA-env(dsa) 조합이다 — 굵은 셀이 각 행의 winner다. 단위 tok/s.
| model | corpus | van(OFF) | van(ON) | DSA(ON) | suf(OFF) | suf(ON) | suf+dsa(ON) | winner |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-7B-Instruct | sharegpt | 4,189 | 5,600 | 5,640 | 6,167 | 6,058 | 6,164 | suf(OFF) |
| swebench | 4,120 | 5,871 | 5,973 | 5,416 | 5,322 | 5,551 | DSA(ON) | |
| humaneval | 3,754 | 5,331 | 5,336 | 5,213 | 4,863 | 4,989 | DSA(ON) | |
| mbpp | 3,814 | 5,931 | 5,965 | 5,506 | 5,346 | 5,390 | DSA(ON) | |
| wildchat | 4,184 | 5,694 | 5,644 | 6,285 | 5,974 | 6,293 | suf+dsa(ON) | |
| lmsys | 4,090 | 5,409 | 5,427 | 5,956 | 5,906 | 6,038 | suf+dsa(ON) | |
| mix | 4,169 | 5,564 | 5,572 | 7,803 | 7,478 | 7,457 | suf(OFF) | |
| DS-R1-Distill-Qwen-7B | sharegpt | 8,724 | 12,232 | 12,170 | 11,961 | 11,234 | 11,240 | van(ON) |
| swebench | 8,835 | 11,891 | 11,888 | 15,422 | 14,671 | 14,682 | suf(OFF) | |
| humaneval | 8,159 | 11,273 | 11,240 | 11,459 | 11,035 | 10,519 | suf(OFF) | |
| mbpp | 8,440 | 11,694 | 11,676 | 12,398 | 11,481 | 12,260 | suf(OFF) | |
| wildchat | 8,925 | 12,319 | 12,210 | 11,717 | 10,795 | 11,263 | van(ON) | |
| lmsys | 8,811 | 12,055 | 12,057 | 11,360 | 11,052 | 11,390 | DSA(ON) | |
| mix | 9,058 | 12,277 | 12,301 | 24,458 | 22,467 | 22,193 | suf(OFF) | |
| Llama-3.1-8B-Instruct | sharegpt | 8,868 | 12,091 | 12,088 | 19,054 | 18,073 | 19,328 | suf+dsa(ON) |
| swebench | 8,348 | 11,970 | 11,518 | 21,353 | 20,735 | 20,518 | suf(OFF) | |
| humaneval | 9,048 | 10,967 | 11,061 | 15,126 | 14,794 | 15,601 | suf+dsa(ON) | |
| mbpp | 8,730 | 12,190 | 12,066 | 17,825 | 17,976 | 17,360 | suf(ON) | |
| wildchat | 9,002 | 12,210 | 12,197 | 19,856 | 19,602 | 19,451 | suf(OFF) | |
| lmsys | 9,074 | 12,528 | 11,993 | 19,862 | 19,361 | 18,905 | suf(OFF) | |
| mix | 8,850 | 12,089 | 12,058 | 27,851 | 24,407 | 26,615 | suf(OFF) | |
| Qwen2.5-32B-Instruct | sharegpt | 3,079 | 4,591 | 4,607 | 4,662 | 4,499 | 4,474 | suf(OFF) |
| swebench | 2,892 | 4,148 | 4,244 | 5,002 | 4,348 | 4,566 | suf(OFF) | |
| humaneval | 2,571 | 3,602 | 3,527 | 4,859 | 4,325 | 4,269 | suf(OFF) | |
| mbpp | 2,915 | 4,295 | 4,425 | 5,138 | 4,826 | 4,817 | suf(OFF) | |
| wildchat | 3,128 | 4,804 | 4,738 | 4,884 | 4,651 | 4,504 | suf(OFF) | |
| lmsys | 3,053 | 4,686 | 4,628 | 4,478 | 4,578 | 4,249 | van(ON) | |
| mix | 3,056 | 4,694 | 4,698 | 6,597 | 5,979 | 6,256 | suf(OFF) | |
| DS-R1-Distill-Qwen-32B | sharegpt | 4,803 | 4,931 | 4,902 | 4,996 | 4,682 | 4,613 | suf(OFF) |
| swebench | 4,409 | 4,524 | 4,561 | 5,241 | 5,589 | 5,444 | suf(ON) | |
| humaneval | 3,462 | 3,729 | 4,208 | 3,771 | 3,935 | 3,435 | DSA(ON) | |
| mbpp | 4,690 | 4,905 | 4,806 | 5,690 | 5,097 | 5,221 | suf(OFF) | |
| wildchat | 4,891 | 5,066 | 5,102 | 5,729 | 5,363 | 5,539 | suf(OFF) | |
| lmsys | 4,898 | 4,993 | 5,011 | 5,356 | 4,980 | 5,116 | suf(OFF) | |
| mix | 4,938 | 5,134 | 5,060 | 9,056 | 8,378 | 9,240 | suf+dsa(ON) | |
| Qwen2.5-72B-Instruct | sharegpt | 2,688 | 2,830 | 2,906 | 3,219 | 3,095 | 3,006 | suf(OFF) |
| swebench | 2,361 | 2,474 | 2,444 | 2,647 | 2,743 | 2,635 | suf(ON) | |
| humaneval | 806 | 1,989 | 2,542 | 2,489 | 2,358 | 2,022 | DSA(ON) | |
| mbpp | 3,395 | 3,417 | 3,441 | 3,234 | 2,976 | 2,910 | DSA(ON) | |
| wildchat | 2,803 | 2,929 | 2,909 | 2,621 | 2,434 | 2,591 | van(ON) | |
| lmsys | 2,807 | 3,169 | 3,083 | 3,429 | 2,978 | 3,153 | suf(OFF) | |
| mix | 2,735 | 2,967 | 2,902 | 5,268 | 5,643 | 5,266 | suf(ON) | |
| Llama-3.1-70B-Instruct | sharegpt | 3,091 | 3,177 | 3,139 | 4,864 | 4,542 | 4,634 | suf(OFF) |
| swebench | 2,878 | 2,809 | 2,968 | 6,026 | 5,949 | 5,455 | suf(OFF) | |
| humaneval | 3,391 | 3,456 | 2,899 | 4,728 | 4,598 | 4,549 | suf(OFF) | |
| mbpp | 1,773 | 1,699 | 1,778 | 3,266 | 3,243 | 2,273 | suf(OFF) | |
| wildchat | 3,172 | 3,213 | 3,268 | 5,261 | 5,142 | 4,966 | suf(OFF) | |
| lmsys | 3,040 | 3,145 | 3,123 | 3,958 | 3,677 | 3,818 | suf(OFF) | |
| mix | 3,129 | 3,206 | 3,192 | 10,400 | 10,247 | 8,829 | suf(OFF) | |
| DS-R1-Distill-Llama-70B | sharegpt | 3,033 | 3,018 | 3,142 | 2,660 | 2,579 | 2,503 | DSA(ON) |
| swebench | 3,236 | 3,142 | 3,182 | 2,739 | 2,739 | 2,642 | van(OFF) | |
| humaneval | 2,852 | 2,828 | 2,812 | 2,788 | 2,809 | 2,718 | van(OFF) | |
| mbpp | 2,777 | 2,989 | 2,954 | 2,426 | 2,328 | 2,265 | van(ON) | |
| wildchat | 3,127 | 3,208 | 3,166 | 2,658 | 2,544 | 2,661 | van(ON) | |
| lmsys | 2,992 | 3,046 | 3,045 | 2,848 | 2,756 | 2,844 | van(ON) | |
| mix | 3,164 | 3,244 | 3,198 | 6,127 | 6,175 | 5,818 | suf(ON) | |
| Llama-3.1-405B-FP8 | sharegpt | 1,217 | 1,239 | 1,229 | 2,061 | — | — | suf(OFF) |
| swebench | 1,204 | 1,211 | 1,239 | 2,639 | — | — | suf(OFF) | |
| humaneval | 1,253 | 1,237 | 1,192 | 2,112 | — | — | suf(OFF) | |
| mbpp | 916 | 883 | 815 | 1,725 | — | — | suf(OFF) | |
| wildchat | 1,280 | 1,267 | 1,263 | 2,290 | — | — | suf(OFF) | |
| lmsys | 1,220 | 1,247 | 1,221 | 2,243 | — | — | suf(OFF) | |
| mix | 1,252 | 1,252 | 1,271 | 2,829 | — | — | suf(OFF) | |
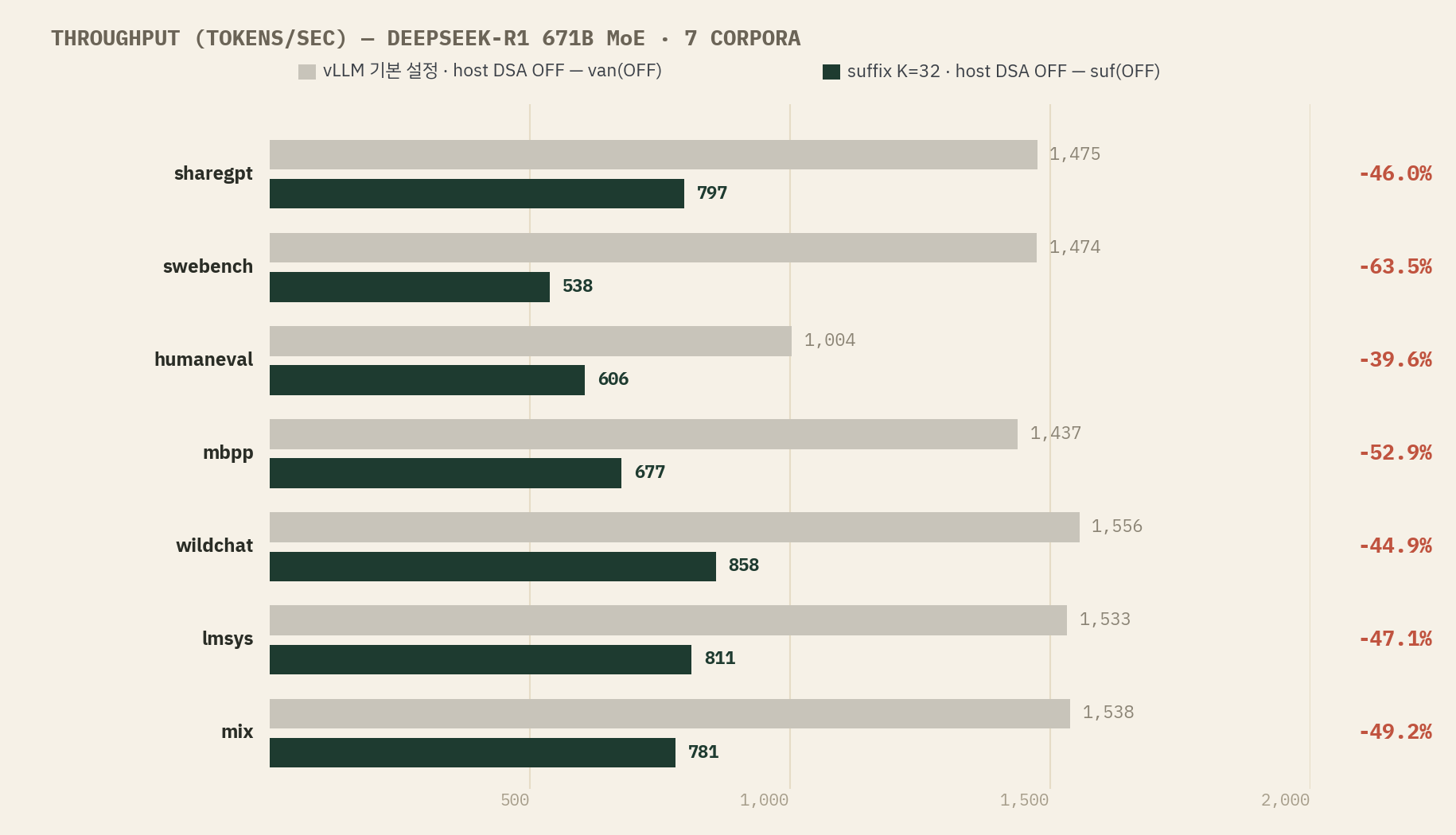
| DeepSeek-R1 (671B MoE) | sharegpt | 1,475 | 1,565 | 1,559 | 797 | 730 | 794 | van(ON) |
| swebench | 1,474 | 1,536 | 1,518 | 538 | 496 | 542 | van(ON) | |
| humaneval | 1,004 | 961 | 858 | 606 | 1,219 | 670 | suf(ON) | |
| mbpp | 1,437 | 1,482 | 1,490 | 677 | 661 | 669 | DSA(ON) | |
| wildchat | 1,556 | 1,614 | 1,614 | 858 | 880 | 824 | van(ON) | |
| lmsys | 1,533 | 1,587 | 1,592 | 811 | 808 | 773 | DSA(ON) | |
| mix | 1,538 | 1,599 | 1,601 | 781 | 754 | 727 | DSA(ON) |
여기까지가 요약이다. suf(OFF)가 70셀 중 36셀의 winner — 전편의 처방은 dense 모델에서는 크기를 가리지 않고 이식되었다. 대신 두 개의 새 경계(405B-FP8의 부팅 한계, 671B MoE의 전면 회귀)와, 설정이 아닌 호스트 상태가 만든 +36%의 정체를 따져야 했다. 차례로 간다.
여섯 개의 측정점
전편과 무엇이 다른가. 축이 세 개 늘었다.
전편이 H100×8에서 모델 하나(+경계 탐색용 small model들)와 synthetic 워크로드로 답했다면, 본 sweep은 세 축을 바꿨다. 하드웨어는 B200×8(sm_100, HBM3e 183 GiB), 모델은 7B dense부터 671B MoE까지 10개, corpus는 sonnet 같은 합성 분포 대신 real trace 7종 — ShareGPT, WildChat, LMSYS, HumanEval, MBPP, SWE-Bench, 그리고 운영 proxy인 mix다.
그리고 축이 하나 더 있다. 측정 도중 호스트의 Intel DSA(Data Streaming Accelerator) work queue 상태가 vllm 설정과 무관하게 결과를 흔든다는 사실이 확인되어, 이를 별도 차원으로 분리했다. 그 결과가 모델×corpus 당 6개의 측정점이다.
| ID | label | host DSA WQ | spec decode | vllm DSA env | 출처 |
|---|---|---|---|---|---|
| ① | van(OFF) | disabled | — | — | TSK_042 baseline |
| ② | van(ON) | enabled | — | — | 본 실험 |
| ③ | DSA(ON) | enabled | — | VLLM_LHC_DSA=1 | 본 실험 |
| ④ | suf(OFF) | disabled | suffix K=32 | — | TSK_042 baseline |
| ⑤ | suf(ON) | enabled | suffix K=32 | — | 본 실험 |
| ⑥ | suf+dsa(ON) | enabled | suffix K=32 | on | 본 실험 |
suffix 설정은 전편의 dominant 구성을 그대로 승계했다 — {"method":"suffix","num_speculative_tokens":32},
tree depth·cache 등 나머지는 default. vllm DSA env(③⑥)는 host↔pinned memcpy를 DSA로 오프로드하는 lever로,
VLLM_LHC_DSA=1 VLLM_LEVER_N9=1 VLLM_LHC_DSA_MIN=65536(64 KiB 미만 copy는 CPU 경로 유지)이다.
벤치마크는 real trace prompt에 concurrency 32, max_tokens 8,192, streaming — 7개 corpus 전부 동일 harness다.
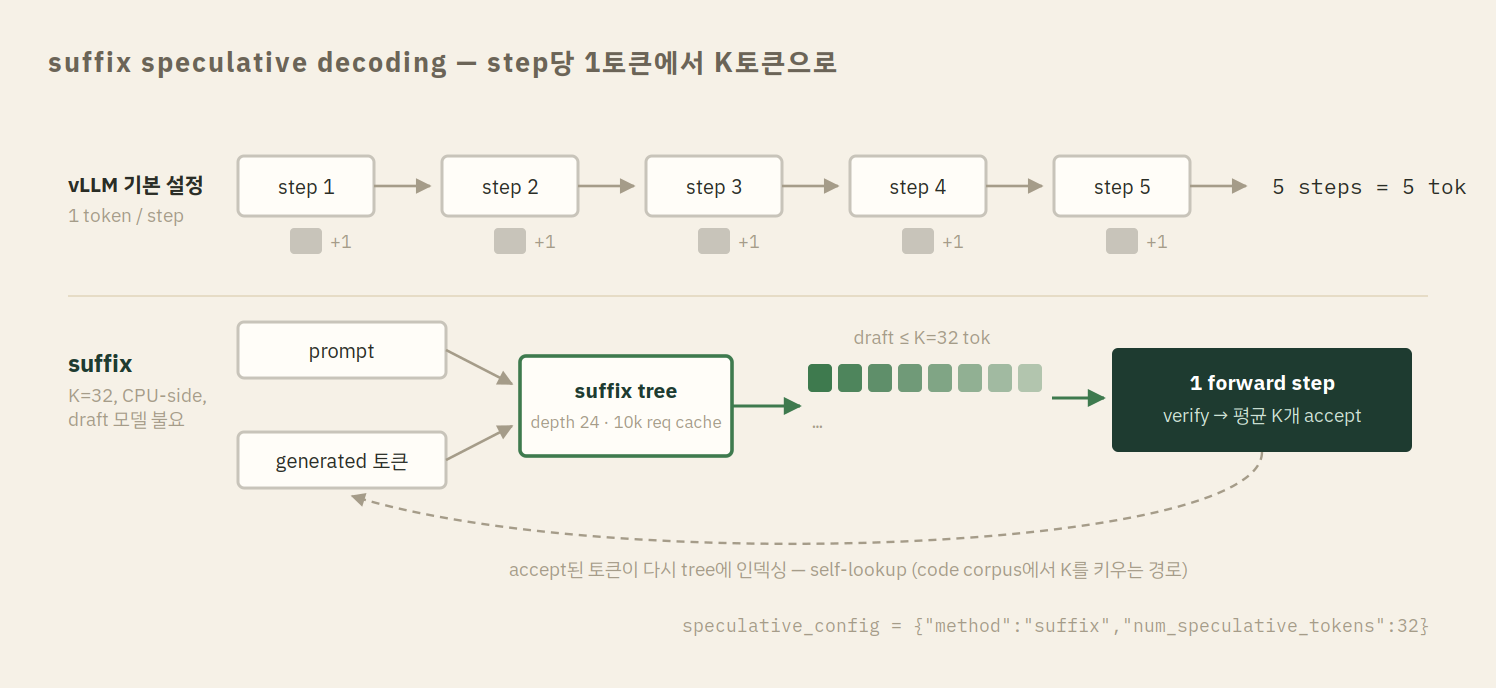
전편의 결론은 살아남았는가
36/70셀. 부등식은 살아남았고, 상수는 이동했다.
70개 (모델, corpus) 셀에서 6개 측정점 중 winner의 분포는 다음과 같다.
| winner | 셀 수 | 비고 |
|---|---|---|
| ④ suf(OFF) | 36 | 전체의 절반 이상. suffix decoding이 dominant lever |
| ② van(ON) | 11 | 대부분 DS-Distill-Llama-70B와 671B MoE |
| ③ DSA(ON) | 11 | ②와 통계적으로 구분 어려움(§05) |
| ⑤ suf(ON) | 6 | 조합 lever가 이기는 셀은 소수, corpus-dependent |
| ⑥ suf+dsa(ON) | 4 | |
| ① van(OFF) | 2 | DS-Distill-Llama-70B 일부 corpus |
전편의 첫 번째 결론 — 가속의 대부분은 suffix decoding을 켜는 것 자체에서 나온다 — 은 모델 10개로 확장해도 그대로다. 표준 dense 모델(Qwen 7B/32B/72B, Llama 8B/70B/405B)에서 suffix는 corpus를 불문하고 +50~+232%의 suf-gain을 만들었고, DSA 계열 lever들은 그 위에서 ±10% 안쪽을 오갔다.
다만, 7B 경계는 이동했다
전편에서 가장 단호하게 썼던 문장이 하나 있다. “7B 이하 모델에서는 무엇을 켜도 느려진다.” 본 sweep에서 이 문장은 깨졌다. Qwen2.5-7B는 mix에서 +87.2%, Llama-3.1-8B는 +214.7%, DS-Distill-Qwen-7B는 +170.0% — 전부 suffix가 큰 폭의 net-positive다.
모순처럼 보이지만, 전편의 mechanism으로 돌아가면 오히려 일관적이다. 가속·회귀를 가르는 건 모델 크기가 아니라 부등식 K > R — 평균 채택 토큰 수가 spec step overhead 배수를 넘느냐 — 이고, 모델 크기는 R을, corpus는 K를 움직이는 변수일 뿐이다. 전편의 7B 회귀는 word-salad code 같은 synthetic corpus에서 K가 바닥이었던 환경의 결론이고, 본 실험의 real chat trace(ShareGPT·WildChat)는 반복 구조가 풍부해 suffix tree의 K가 충분히 커진다. 하드웨어가 H100에서 B200으로 바뀐 것도 상수를 움직였을 것이다. 즉 부등식은 환경을 건너 살아남았고, “7B”라는 숫자는 그 환경의 상수였다. 경계를 모델 크기로 외우지 말고, 자기 corpus에서 K를 재라는 것이 수정된 교훈이다.
corpus별 결이 남아 있다는 점도 같다. DS-Distill-Qwen-7B는 mix에서 +170%지만 sharegpt·wildchat에서는 van(ON)이 suffix를 이긴다. mix 셀의 suf-gain이 개별 corpus보다 일관되게 큰 것도 눈에 띄는 패턴인데 (Llama-70B: per-corpus 최대 6,026 vs mix 10,400), 이질적 요청이 섞일 때 global suffix tree의 hit 기회가 늘어나는 효과로 보이나 본 실험에서 분리 검증하지는 않았다 — mix 수치를 단일 corpus 운영에 그대로 외삽하면 안 된다(§08).
+36%의 정체
설정을 하나도 바꾸지 않았는데, 기본 설정 측정값이 빨라졌다.
이번 측정에서 가장 시간을 쓴 건 suffix가 아니라 이쪽이다.
TSK_042 baseline(6월 2일)과 본 실험(6월 10일~)의 vLLM 기본 설정을 비교하니, vllm 설정이 동일한데도
7~8B 모델에서 +33~+36%, Qwen-32B에서는 +53.6%의 차이가 났다. 두 측정 사이에 바뀐 호스트 상태는 하나 —
6월 8일, LHC Phase 작업의 일환으로 /sys/bus/dsa/devices/wq*/state의
DSA work queue 8개(dsa0/dsa1 × 4)가 enable된 것이다.
| 측정 시점 | host DSA WQ | 해당 측정점 |
|---|---|---|
| 2026-06-02 (TSK_042) | DISABLED | ① van(OFF) · ④ suf(OFF) |
| 2026-06-08 00:40 | wq enable (sysfs mtime 실측) — LHC Phase 작업 | |
| 2026-06-10+ (본 실험) | ENABLED | ② ③ ⑤ ⑥ |

효과는 method에 따라 차등적이다. host-bound regime인 vLLM 기본 설정에서는 +33~+36%(소형 모델 기준 — 70B급은 +2~8%, 405B는 0%로 모델이 클수록 희석), step-bound regime인 suffix에서는 −5~+10%로 효과가 없거나 약한 손해다. 즉 이 효과가 실재한다면 “host memcpy가 병목인 구간”에서만 작동하는 lever라는 해석과 부합한다.
clients=0 — 즉 어떤 프로세스도 WQ를 실제로 사용하고 있지 않았다.
한편 ①④의 출처인 TSK_042와 본 실험은 cudagraph 경로가 다를 수 있어(PIECEWISE → FULL_AND_PIECEWISE),
+36%의 진짜 원인이 cudagraph_mode 차이라는 가설이 현재 유력하다(SUB_213).
본 글에서 ON/OFF는 “그 시점 호스트 상태”의 라벨로만 쓰며, 인과는 격리 검증(verify_dsa.sh C1/C2/C3) 결과를 기다린다.
운영 관점의 함의는 인과와 무관하게 분명하다. vllm 인자 바깥의 호스트 상태가 측정을 수십 % 단위로 흔들 수 있다는 것.
전편 §09-6에서 “측정 조건이 다른 값끼리 직접 비교하지 말라”고 썼는데, 그 목록에 sysfs 레벨의 호스트 구성까지 들어가야 한다는 걸
이번에 측정으로 배웠다. 참고로 이 WQ 구성은 /etc/accel-config/에 저장돼 있지 않은 수동 enable 상태라
재부팅하면 소실된다 — 재현이 필요하면 accel-config save-config가 선행돼야 한다.
vllm 레벨 DSA env는 부차적이다
호스트가 driver, env는 noise.
그렇다면 vllm 프로세스가 명시적으로 DSA lane을 쓰도록 하는 env(③⑥)는 어떤가.
VLLM_LHC_DSA=1 # LHC DSA lane 활성 (default off)
VLLM_LEVER_N9=1 # host↔pinned memcpy DSA 오프로드
VLLM_LHC_DSA_MIN=65536 # 64 KiB 미만 copy는 CPU 경로 유지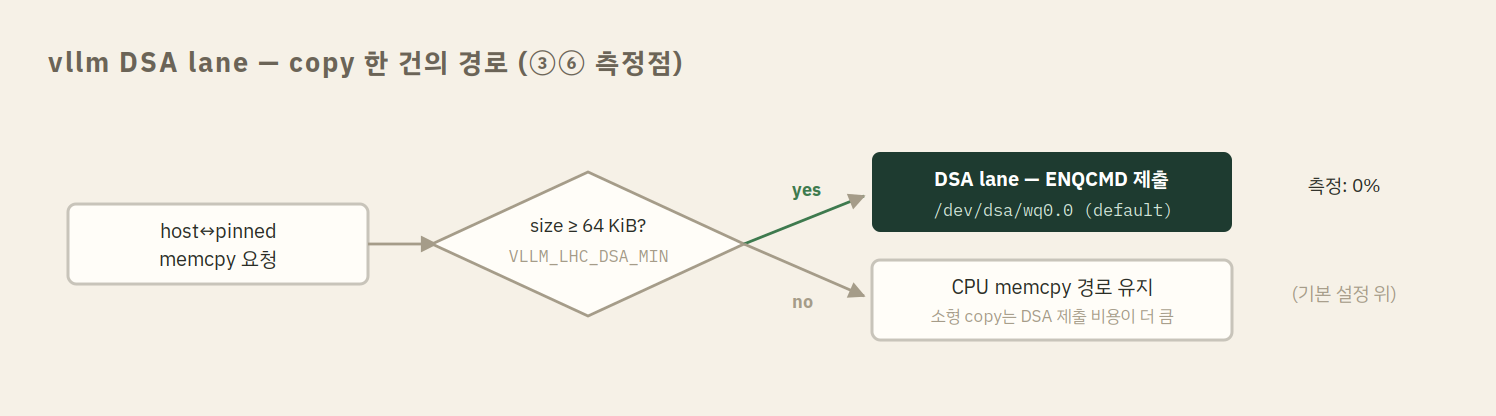
VLLM_LEVER_N9=1이 켜진 프로세스의 host↔pinned copy는 64 KiB를 기준으로 DSA lane과 CPU 경로로 분기한다. 경로 자체는 동작하지만, throughput에 남기는 흔적은 vLLM 기본 설정 위 0%, suffix 위 ±5%였다.결과는 깔끔하게 심심하다. vLLM 기본 설정 위(③ vs ②)에서는 0% — 10개 모델의 mix 기준 −2.2~+1.5%로 noise 범위다. suffix 위(⑥ vs ⑤)에서는 ±5% 안팎의 corpus-dependent 진동이 있을 뿐 dominant signal이 없다 (Llama-8B +9.0%와 Llama-70B −13.8%가 공존한다). §04의 호스트 상태 효과가 +36%였던 것과 비교하면 결론은 하나다 — 이 축에서는 호스트 구성이 driver이고, vllm env는 부차적이다. ⑥이 winner인 셀이 70개 중 4개 있긴 하지만, 운영 정책의 default로 삼을 근거는 못 된다.
새로 만난 두 개의 경계
하나는 부팅에서, 하나는 아키텍처에서.
경계 1 — Llama-405B-FP8은 suffix로 부팅이 안 된다
405B-FP8에 suffix K=32를 붙이면 engine init에서 num_gpu_blocks=0 → override=512 후
core proc가 crash한다. 405B-FP8 + suffix K=32 + B200 단일 노드 TP=8 + gmu 0.85 조합의 호환성 한계로,
⑤⑥ 14셀이 영구 미측정으로 남았다(406/420의 결손이 전부 여기다). 흥미로운 건 host-OFF 시점의
④는 멀쩡히 측정되어 +125.9%라는, 9개 dense 모델 중에서도 상위권의 suf-gain을 보였다는 점이다.
즉 405B에서 suffix는 “효과가 없는” 게 아니라 “현재 빌드·메모리 구성에서 못 켜는” 상태다 —
gmu·K를 낮춘 재시도가 후속 과제다.
경계 2 — 671B MoE에서 suffix는 전면 회귀한다
DeepSeek-R1(671B MoE, active 37B)은 본 실험에서 suffix가 7개 corpus 전부 net-negative인 유일한 모델이다. mix 기준 −49.2%, swebench에서는 1,474 → 538 tok/s로 거의 1/3토막이다. dense 405B가 +126%인 것과 정확히 대비된다. 메커니즘 규명은 본 실험의 범위 밖이라 단정하지 않겠다 — 관측 사실로서 기록하는 것은, “크면 클수록 spec decoding이 유리하다”는 dense에서의 직관이 MoE에는 이식되지 않는다는 점이다. 전편에서 same-size cross-vendor 차이(Llama 70B vs Qwen 72B)를 “architecture가 spec 효과를 가른다”는 신호로 읽었는데, MoE는 그 신호의 극단값인 셈이다. 671B MoE의 운영 정답은 현재로선 vLLM 기본 설정이다.
실전 적용 — production decision tree, 갱신판
전편의 트리에 행을 추가하고, 한 행을 수정한다.
| 모델군 | 권장 lever | 근거 (mix, vs van 동일 host state) |
|---|---|---|
| 표준 dense 7B~405B Qwen 7/32/72B · Llama 8/70/405B |
④ suf(OFF) — suffix K=32 | +50 ~ +232% |
| reasoning distill 32B DS-Distill-Qwen-32B |
⑥ suf+dsa(ON) | mix 9,240으로 최고치 — 단 corpus-dependent, 분리 측정 후 적용 |
| reasoning distill 70B DS-Distill-Llama-70B |
⑤ suf(ON) | mix +90%, 단 개별 corpus에서는 vLLM 기본 설정과 백중 — mix성 트래픽일 때만 |
| 671B MoE DeepSeek-R1 |
vLLM 기본 설정 — suffix 금지 | suffix 시 −49 ~ −53% |
| 405B-FP8 + suffix | 현 빌드에서 부팅 불가 | gmu/K 하향 재시도 전까지 ④ 구성은 host-OFF baseline 수치로만 참고 |
전편 대비 수정 사항은 두 가지다. 첫째, “≤7B는 vLLM 기본 설정” 행을 삭제한다 — real trace corpus에서는 7~8B도 suffix가 분명한 net-positive다(§03). 둘째, “MoE는 별도 검증 전까지 vLLM 기본 설정” 행을 추가한다. 부팅 인자는 전편과 동일 골격이고, 본 실험에서 쓴 형태는 이렇다.
# server boot (sweep_corpus.sh)
--speculative-config '{"method":"suffix","num_speculative_tokens":32}'
# gpu_memory_utilization=0.85, max_model_len=16384, cudagraph FULL_AND_PIECEWISE
# 공통 env
export ARCTIC_INFERENCE_ENABLED=0 VLLM_PLUGINS=""
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
export VLLM_NGRAM_NUM_THREADS_CAP=8 VLLM_NGRAM_DIVIDE_BY_TP=0vllm DSA env(③⑥용 VLLM_LHC_DSA=1 ...)는 §05의 결론대로 default-off를 권장한다.
회피해야 할 함정들
이번 실험에서 새로 추가된 목록.
- 시점이 다른 측정을 같은 baseline으로 합치기. vllm 인자가 동일해도 호스트 sysfs 상태(DSA WQ)나 cudagraph 경로가 다르면 vLLM 기본 설정부터 +36% 어긋난다. baseline 재사용 전에 호스트 구성의 diff를 박제하라.
- 671B MoE에 dense의 직관으로 suffix를 켜기. 7개 corpus 전원 회귀, 최대 −53%. dense에서의 +232%와 같은 설정이다.
- 405B-FP8에 suffix K=32를 그대로 붙이기. engine init 단계에서 crash. gmu 0.85 기준이며, 켜기 전에 KV block 수부터 확인.
- vllm DSA env에 기대를 걸기. vLLM 기본 설정 위 0%, suffix 위 ±5% noise. 이 축의 driver는 호스트 구성이다.
- 호스트 DSA WQ 구성을 영속이라고 믿기.
accel-config save-config없이는 재부팅 시 소실 — 어느 날 갑자기 “성능이 예전과 다른” 미스터리의 씨앗이 된다. - mix corpus 수치를 단일 corpus 운영에 외삽하기. mix의 suf-gain은 개별 corpus보다 일관되게 크다. 자기 트래픽 분포로 분리 측정이 먼저다.
정리하면
세 줄로.
첫째, 전편의 처방은 dense 모델에서는 크기를 가리지 않고 이식된다. suffix K=32 하나로 7B부터 405B까지 +50~+232%, 70셀 중 36셀의 winner. 전편의 “7B 경계”는 모델의 속성이 아니라 그 corpus·하드웨어의 상수였고, K > R 부등식만이 환경을 건너 살아남았다.
둘째, 설정 바깥의 호스트 상태가 측정을 흔든다. DSA WQ enable 전후로 vLLM 기본 설정이 +33~36% 차이 났지만
clients=0이 확인되어 cudagraph mode 차이가 진범이라는 가설이 유력하다 — 인과는 격리 검증으로 가린다.
확실한 교훈은 하나다: baseline을 재사용하려면 vllm 인자만이 아니라 호스트 구성까지 같아야 한다.
셋째, 아키텍처가 새 경계를 만든다. dense 405B는 +126%인데 671B MoE는 전 corpus −49%. “클수록 spec이 유리하다”는 dense의 직관은 MoE 앞에서 멈춘다. vllm 레벨 DSA env는 어느 쪽에서도 부차적이었다.
측정 환경: DGX B200 – NVIDIA B200×8 (sm_100, HBM3e 183 GiB, NVLink5) · Intel Xeon Platinum 8570 ×2 (224 thread, AMX/AVX-512/DSA) ·
vLLM 1.7.dev (sm_100 빌드) · cudagraph FULL_AND_PIECEWISE · gmu 0.85 · max_model_len 16,384 ·
real-trace prompts, concurrency 32, max_tokens 8,192, streaming.
10개 모델(Qwen2.5 7/32/72B · DS-R1-Distill 7/32/70B · Llama-3.1 8/70/405B-FP8 · DeepSeek-R1) × 7개 corpus
(sharegpt · wildchat · lmsys · humaneval · mbpp · swebench · mix) × 6개 측정점 = 406/420셀.
· 본 실험: 2026-06-10+.