코드 한 줄 고치지 않고, vLLM에 이미 들어 있는 내장 설정만으로 Llama-3.3-70B 추론을 6개 워크로드 전부 가속한 156셀 측정 리포트.
vLLM 소스에는 손대지 않았다. speculative_config, cudagraph_mode, gpu_memory_utilization — vLLM이 이미 제공하는 내장 설정 몇 개를 켜고 조합했을 뿐인데, Llama-3.3-70B (TP=8, H100×8) 환경에서 6개 워크로드 모두 throughput이 net-positive로 올랐다. sonnet 기준 +52%, chat은 +69%. 다만 이 설정들은 아무 때나 켜면 오히려 느려진다. 이 글은 언제·무엇을 켜야 하는지를 156셀의 측정으로 채운 기록이다.
01한 장의 그림으로
먼저 결과부터. 6개 워크로드, 두 가지 설정.
같은 GPU, 같은 모델, 같은 측정 조건이다. spec decoding을 끈 vanilla와, vLLM 내장 설정만 조합한 최적 구성 — cudagraph_mode="PIECEWISE" + method="suffix" + num_speculative_tokens=32 + gpu_memory_utilization=0.80 — 의 비교다. 이 글에서는 이 구성을 편의상 Trident라 부르겠다.
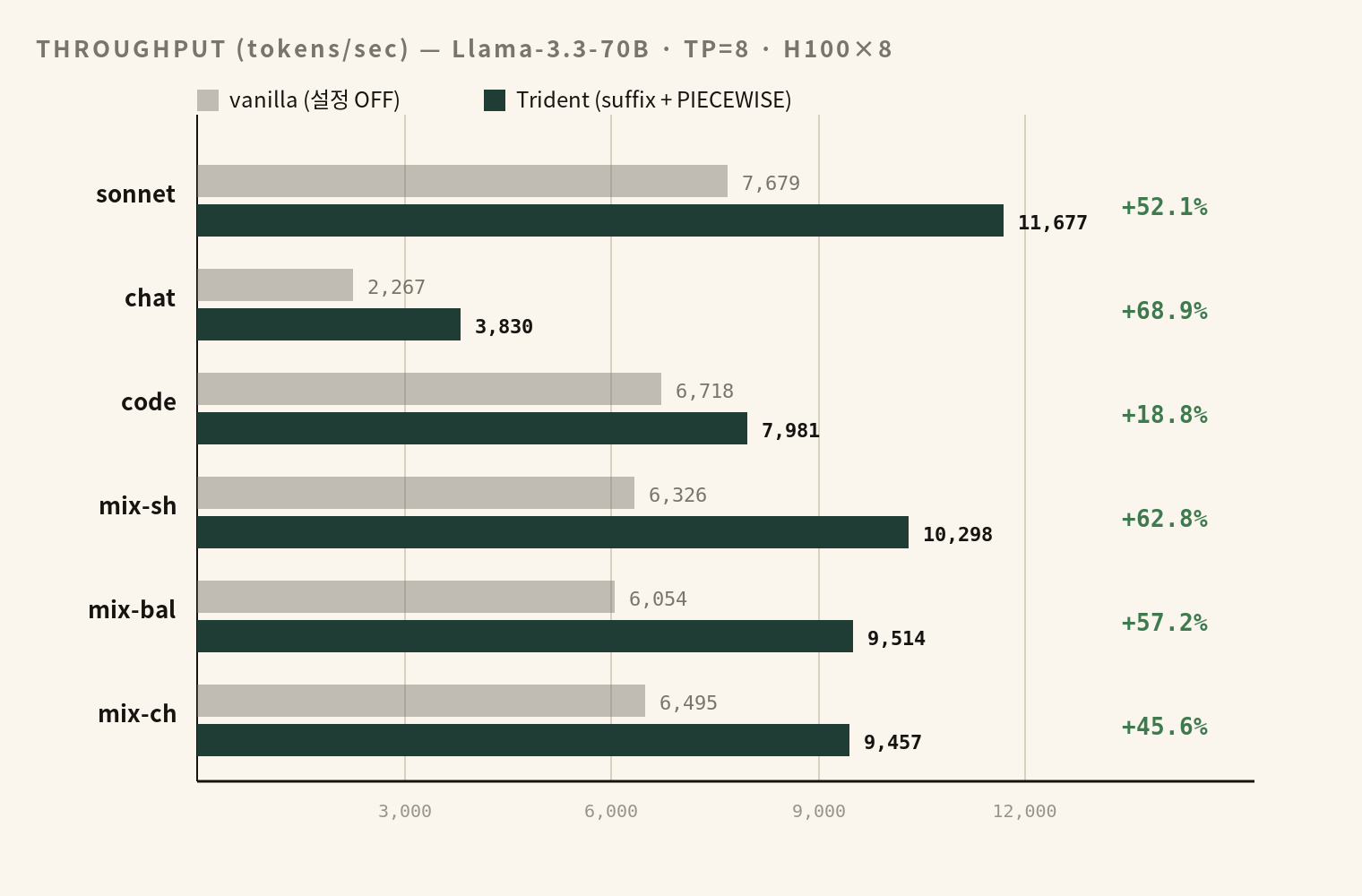
여기까지가 결과 요약이다. 6개 워크로드 모두 +18.8%부터 +68.9%까지 향상, wall time 31% 단축. 그리고 이걸 만든 건 딱 네 개의 vLLM 내장 설정이다.
02딱 네 개의 설정
전부 vLLM에 이미 들어 있다. 켜기만 하면 된다.
위 그래프의 가속은 다음 네 개의 lever를 조합한 결과다. 새 라이브러리도, 소스 패치도 없다. LLM() 생성자에 인자 몇 개를 넘기는 게 전부다.
speculative_config— speculative decoding을 켜는 스위치. drafter가 다음 토큰 여러 개를 미리 추측하고 본 모델이 한 번에 검증한다. 받아들여지는 토큰이 많을수록 forward step 수가 줄어 빨라진다.method(ngram vs suffix) — drafter가 후보를 어디서 찾는지. ngram은 prompt 안에서만, suffix는 prompt와 이미 생성한 토큰 양쪽에서 찾는다. 이 차이가 워크로드별 성패를 가른다.num_speculative_tokens— 한 번에 몇 개를 추측할지. ngram은 7, suffix는 32가 본 환경의 sweet spot이다.cudagraph_mode="PIECEWISE"+gpu_memory_utilization=0.80— suffix의 가변 draft 길이를 CUDA graph가 매번 다시 캡처하지 않도록 PIECEWISE로 자르고, 그만큼 필요한 메모리 여유를 gmu를 낮춰 확보한다.
중요한 건 “이걸 켜면 무조건 빨라진다”가 아니라는 점이다. 같은 설정이 어떤 워크로드에서는 +52%, 어떤 워크로드에서는 −20% 회귀를 만든다. 7B 이하 모델에서는 무엇을 켜도 느려진다. 그래서 핵심 질문은 “어떻게 켜느냐”가 아니라 “언제 켜느냐”다. 그 답을 다음 절의 단일 부등식이 설명한다.
03모든 결과를 관통하는 하나의 부등식
왜 어떤 워크로드는 가속이고 어떤 워크로드는 회귀인가.
이 모든 측정 결과를 한 개의 부등식으로 설명할 수 있다. speculative decoding의 가속·회귀 여부는 K와 R의 대소관계가 결정한다.
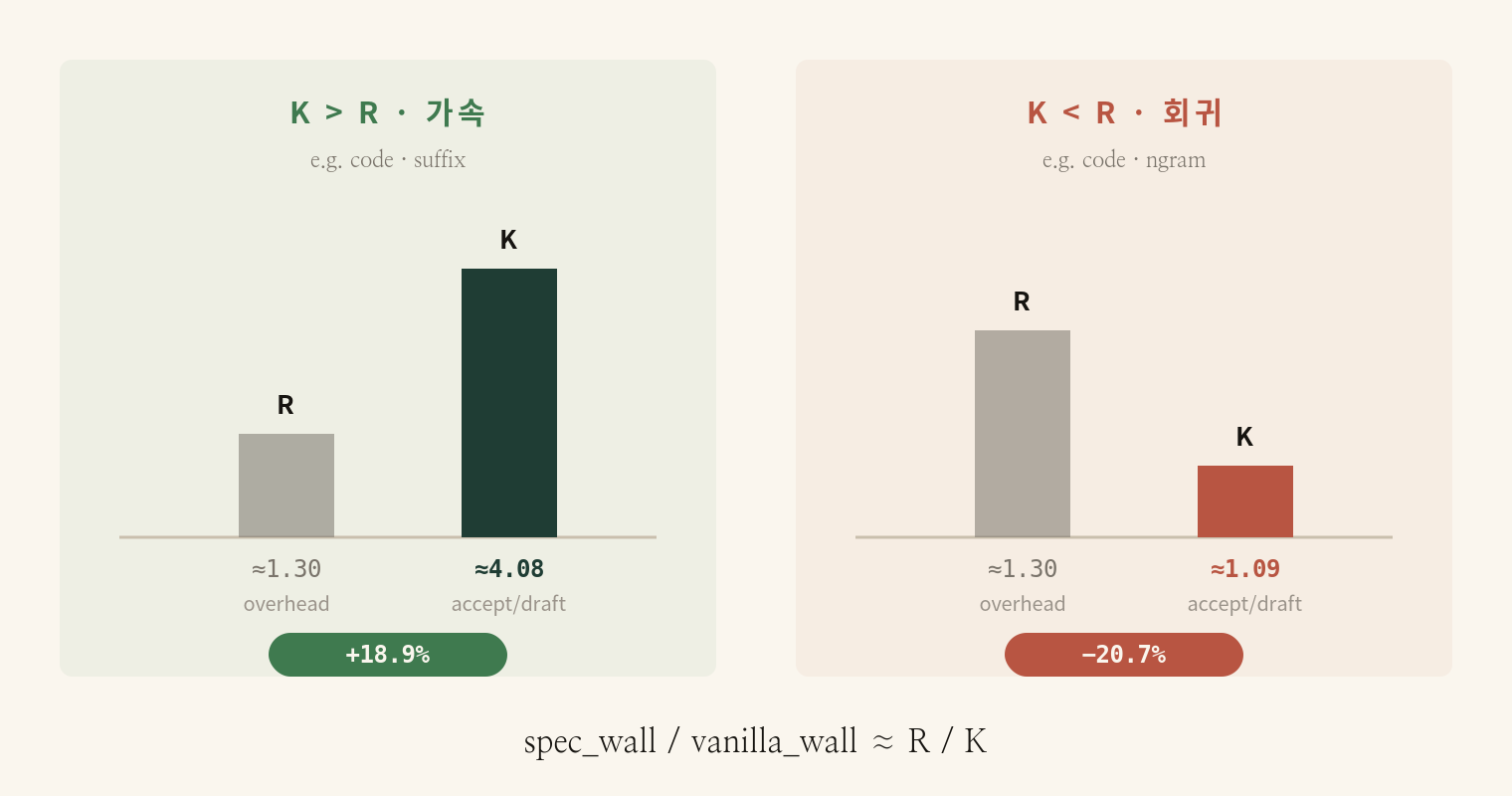
R은 spec step 한 번의 overhead(vanilla step time 대비 배수)이고, K는 한 draft 사이클에서 평균적으로 받아들여지는 토큰의 수다. 본 환경에서 R은 대략 1.25~1.40 사이로 워크로드와 거의 무관하게 일정하다. 따라서 모든 변동은 사실상 K에서 온다.
Leviathan et al. (ICML 2023)의 closed-form은 K = (1−α^(γ+1))/(1−α)지만, 본 환경 ngram drafter의 실측은 linear 근사 K ≈ 1 + α × γ가 더 잘 맞는다. 이유는 ngram drafter의 per-position acceptance가 i.i.d.가 아니라 strong positive correlation을 갖기 때문이다 — 한 position이 accept되면 다음도 accept될 확률이 높다.
04설정을 하나씩 켜 보면
vanilla에서 시작해 설정 세 개를 차례로 켠다.
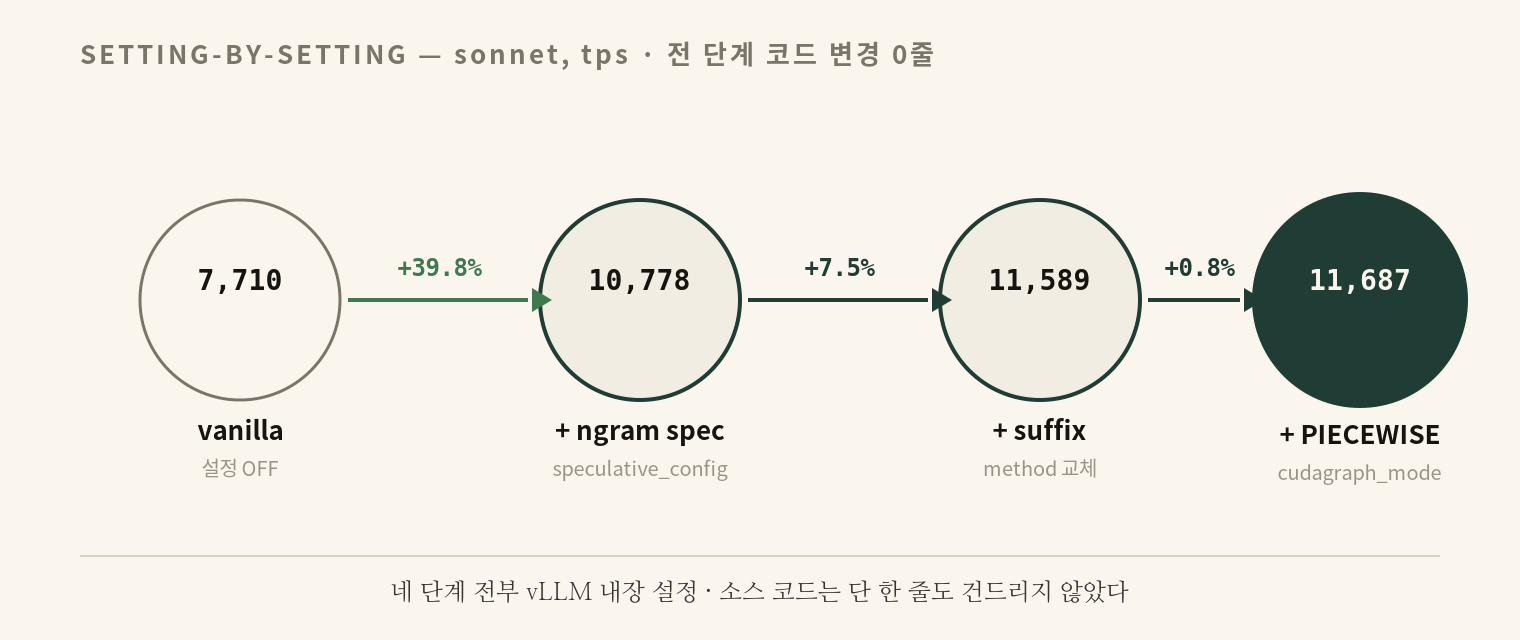
최적 구성은 한 번에 나온 게 아니다. vanilla에서 출발해 vLLM 내장 설정을 하나씩 켜 보면 각 설정이 얼마나 기여하는지 분리해서 볼 수 있다. sonnet 워크로드 기준 throughput 변화는 다음과 같다.
① speculative_config 켜기
vanilla LLM 생성자에 speculative_config={"method":"ngram", "num_speculative_tokens":7, "prompt_lookup_max":5, "prompt_lookup_min":2}를 추가하는 것이 전부다. sonnet 7,710 → 10,778 tps (+39.8%). 향상의 대부분이 이 한 단계에서 나온다. 그만큼 “그냥 안 켜고 있었을 뿐”인 경우가 많다는 뜻이기도 하다.
② suffix decoder로 교체
method를 "ngram"에서 "suffix"로 바꾸고 num_speculative_tokens을 7에서 32로 올린다. 동시에 gpu_memory_utilization을 0.80으로 내려 cudagraph가 쓸 memory headroom을 확보한다. suffix decoder는 prompt와 이전 generation 양쪽을 suffix tree로 인덱싱하기 때문에 K(평균 채택 길이)가 ngram 대비 1.7~3.7배 커지며, 특히 code 워크로드에서는 K가 1.09에서 4.08로 3.74배 향상되어 회귀 영역을 net-positive로 전환시킨다.
③ cudagraph PIECEWISE
compilation_config={"cudagraph_mode":"PIECEWISE"} 한 줄 추가. vLLM v0.11.0 이후 default가 FULL_AND_PIECEWISE로 바뀌었는데, FULL 모드는 전체 forward를 하나의 그래프로 캡처하므로 suffix의 가변 draft 길이를 처리할 때마다 recapture cost가 발생한다. PIECEWISE는 attention/MLP 단위로 그래프를 잘라 dynamic shape를 허용하면서 launch overhead를 회수한다. 특히 chat 워크로드에서 FULL 대비 eager penalty를 −23%에서 +18.9%로 뒤집는다.
05왜 워크로드마다 다르게 반응하는가
prompt 구조가 결정한다.
같은 spec configuration이 sonnet에서는 +52%, chat에서는 +69%, code에서는 +19%로 나타나는 이유를 단순히 “워크로드가 다르니까”로 끝내지 않고 mechanism으로 설명할 수 있다. 핵심은 K (mean accepted length)와 α (per-position acceptance rate)가 워크로드별 prompt 구조에 어떻게 의존하는지다.
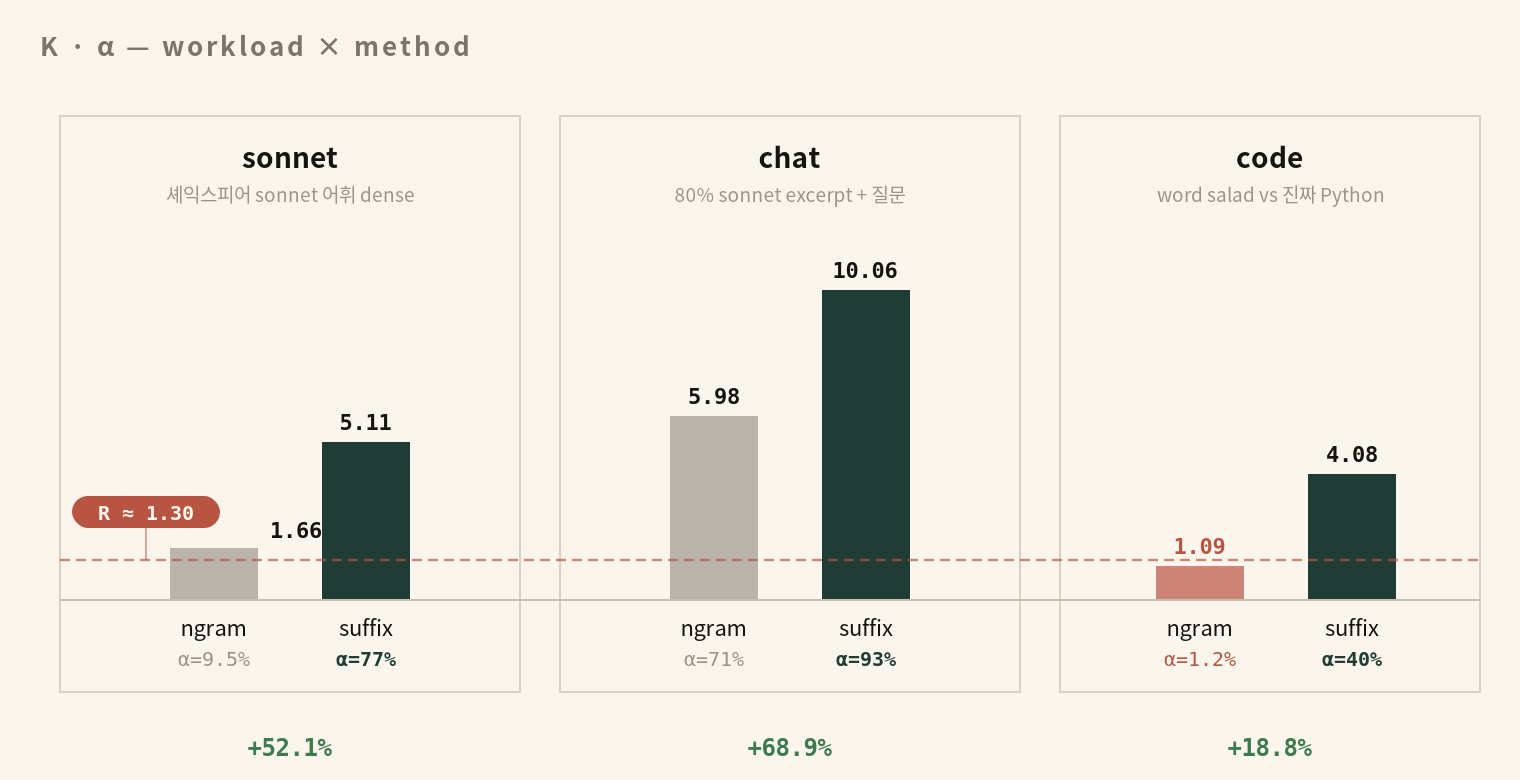
sonnet의 prompt는 셰익스피어 sonnet에서 random sampling한 164줄(전체 517줄 중)로 구성된다. with replacement sampling이므로 birthday problem에 의해 평균 24개의 line이 중복 등장하고, sonnet 어휘 자체가 unique word 5,000 미만으로 제한적이며 thou, thy, love, time 같은 단어가 매우 dense한 bi-gram pool을 형성한다. 결정적으로 generated response가 같은 sonnet style의 continuation이기 때문에 prompt에 이미 등장한 token sequence가 그대로 인용되는 비율이 높다.
chat의 prompt는 흥미롭게도 80%가 sonnet excerpt이고 끝에만 “What is the author’s intent?” 같은 질문이 붙는 형태다. ngram pool 자체는 sonnet과 거의 동일하게 dense하므로 per-draft acceptance가 일어날 때의 K가 sonnet보다 더 높게 나온다 — 이것이 SUB_075의 surprise였다. 사전 예측 sonnet ≫ chat을 뒤집은 결과다. 그러나 응답이 짧기 때문에 (평균 660 token, EOS 조기 도달) coverage가 낮아 throughput 향상폭은 sonnet과 비슷한 수준에 그친다.
code는 builder가 의도적으로 의미 없는 word salad 주석을 채워 넣은 함수 stub이다. prompt 본문이 # comment line N: <8 random words> 형태이고 어휘 pool이 단 8 단어(python, code, function, list, dict, loop, return, test)에 불과해 bi-gram의 unique 가능 조합이 64개뿐이다. 그런데 model이 실제로 생성하는 것은 진짜 Python 코드이므로 prompt의 word salad와 generated code 사이에 공통 토큰이 거의 없다. ngram의 K=1.09, α=1.4%가 나오는 이유다.
여기서 suffix decoder가 code를 net-positive로 끌어올리는 mechanism이 흥미롭다. ngram이 prompt 안에서만 KMP match를 시도하는 반면 suffix는 prompt와 이전 generated tokens 양쪽을 suffix tree로 인덱싱하기 때문에, model이 한 번 생성한 Python keyword(for, if, return, range, len)가 이후 step에서 self-lookup으로 hit된다. 결과적으로 code 워크로드에서 K가 3.74배, α가 33배 증가하여 K > R 조건을 만족하게 된다.
06모델 크기는 어디까지 spec decoding을 허용하는가
7B와 14B 사이 어딘가의 경계.
spec decoding은 무료가 아니다. R이 vanilla step time에 비례하여 늘어나기 때문에, vanilla step time이 짧은 small model에서는 R이 폭증해서 어떤 K로도 따라잡을 수 없게 된다. 5개 모델·2개 하드웨어 cross-validation으로 이게 universal regression임이 입증되었다.
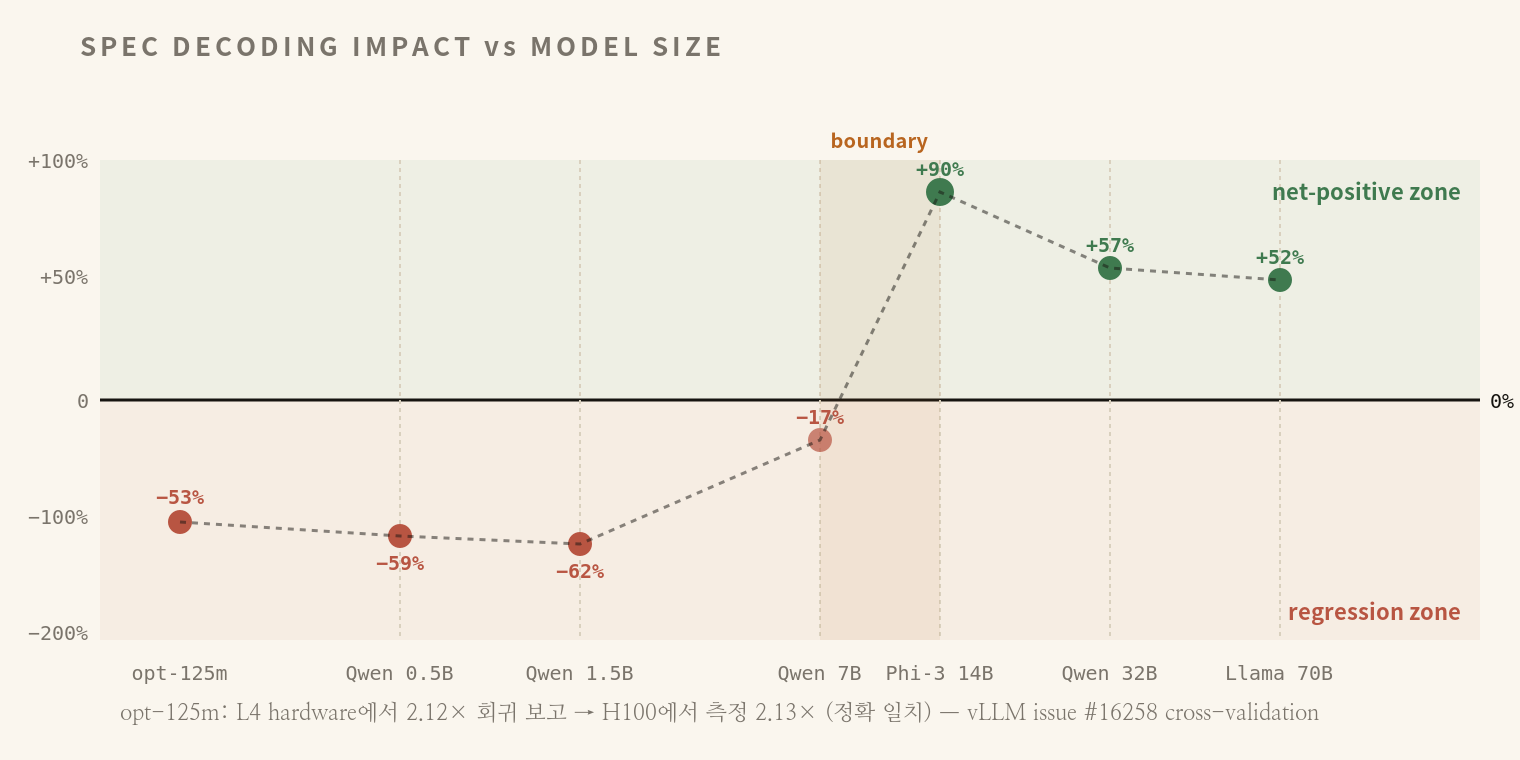
opt-125m을 ngram과 함께 돌리면 외부 vLLM Issue #16258 (2×L4 환경)에서 2.12배 회귀가 보고되었다. 같은 모델을 H100×1 환경에서 측정한 결과 2.13배 회귀라는 정확한 일치를 얻었다. starcoder2-3b 2.30배, Qwen 0.5B 2.46배, Qwen 1.5B 2.63배 회귀, suffix를 써도 회귀 — 5개 모델, 2개 하드웨어, 2개 spec method 모두에서 small model의 universal regression이 hardware-independent임이 확인되었다. 즉 작은 모델에서는 설정을 켜는 것 자체가 손해다.
boundary가 어디인지는 SUB_090과 SUB_096의 추가 측정으로 좁혀졌다. Qwen 7B의 ngram이 −17.3%로 boundary에 근접했고 (여전히 회귀이지만 폭이 작아짐), Phi-3-medium 14B는 6/6 워크로드 모두 net-positive (sonnet +90%, mix-balanced +117%). 따라서 boundary는 7B와 14B 사이에 있다.
흥미로운 부수 관찰은 same-size cross-vendor 차이다. Llama 3.3-70B는 6/6 모두 net-positive (+19%~+69%)인데 비해 Qwen 2.5-72B는 code 워크로드에서만 −5%로 회귀하는 5/6 결과였다. 모델 architecture가 spec acceptance에 정량적으로 영향을 미친다는 첫 관측이며, “model size가 같다고 같은 spec 효과를 기대하면 안 된다”는 경계 신호다.
07실전 적용 — production decision tree
모델 크기와 vendor를 보고 결정한다.
- ≤ 7B (small model) — 어떤 spec method도 net-negative. vanilla만 사용. 5개 모델 cross-validation 결과이며, hardware-independent.
- 14B class (Phi-3 14B 확인) — Trident 설정 즉시 적용. 6/6 net-positive.
- 32B class (Qwen 32B 확인) — Trident 설정 권장. sonnet/chat/code 모두 net-positive.
- 70~72B class — vendor에 따른 미세 조정. Llama 3.3-70B는 6/6 net-positive이므로 Trident 설정 그대로, Qwen 2.5-72B는 code 워크로드 비중이 높으면 vanilla로 떨어뜨리는 운영 정책이 안전.
활성화 코드는 단일 LLM 생성자 호출로 정리된다. 별도 patch 없이 vLLM built-in flag만 사용한다.
from vllm import LLM, SamplingParams
llm = LLM(
model="meta-llama/Llama-3.3-70B-Instruct",
tensor_parallel_size=8,
max_model_len=16384,
max_num_seqs=256,
gpu_memory_utilization=0.80, # cudagraph headroom
enforce_eager=False,
kv_cache_dtype="fp8",
max_num_batched_tokens=8192,
disable_log_stats=True,
seed=0,
compilation_config={"cudagraph_mode": "PIECEWISE"},
speculative_config={
"method": "suffix",
"num_speculative_tokens": 32,
},
)환경 설정에서 빠뜨리면 안 되는 두 가지 env가 있다. 하나는 ARCTIC_INFERENCE_ENABLED=0과 VLLM_PLUGINS=""으로 arctic_inference plugin auto-load를 차단하는 것이고 (plugin은 vLLM 1.6과 binary incompat이지만 SuffixDecodingCache class는 lazy import로 사용 가능), 다른 하나는 PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True로 cudagraph PIECEWISE와 함께 발생할 수 있는 memory fragmentation을 줄이는 것이다.
08역설처럼 보이는 GPU 활용률 하락
GPU 사용량이 줄었는데 throughput이 늘었다.

vanilla는 매 forward step에서 1 token만 진척하는 데 비해, spec decode는 K(≈3~6) token을 한 번에 진척한다. 같은 출력 길이에 도달하기까지 필요한 GPU forward 호출 횟수 자체가 줄기 때문에 wall time이 31% 단축된다. GPU 활용률은 부수 지표이지 목표 지표가 아니라는 점이 이 측정에서 드러나는 직관에 반하는 사실이다 — production engineer가 GPU%를 KPI로 삼고 있다면 이 패턴에서 잘못된 결론에 도달할 수 있다.
09회피해야 할 함정들
측정 과정에서 발견한 회귀 패턴.
- 7B 이하 model에서 spec decoding을 켜둔 채로 운영하기. 어떤 K로도 R을 못 따라가서 throughput이 1.2~2.6배 떨어진다.
- chat 워크로드를
cudagraph_mode="FULL"로 돌리기. eager penalty가 −23%까지 발생하지만PIECEWISE로 바꾸면 완전히 사라지고 +18.9%로 회복. num_speculative_tokens을 너무 크게(>10) 잡기. accept rate가 급락하고 KV memory 압박이 늘어 OOM 가능. ngram은 sonnet에서 7, suffix는 32가 본 환경 sweet spot.prompt_lookup_min을 너무 작게(=1) 잡기. 흔한 unigram까지 후보가 되어 acceptance 떨어진다. 권장값 2.- 워크로드 분리 측정 없이 spec config 판단. 같은 config가 sonnet에서는 가속, code에서는 회귀 — R/K mechanism이 워크로드별로 다르기 때문에 분리 측정 없이는 잘못된 결론에 도달.
- 측정 조건이 다른 값끼리 직접 비교하기. wrapper,
gpu_memory_utilization, cudagraph mode만 바꿔도 같은 vanilla가 수십 % 차이 난다. 설정의 진짜 효과를 보려면 한 가지만 바꾸고 나머지는 고정한 채 비교해야 한다.
10정리하면
세 줄로.
첫째, 코드 한 줄 고치지 않고 vLLM 내장 설정만 정확히 조합하면 큰 가속이 나온다. 최적 구성은 gpu_memory_utilization=0.80, compilation_config={"cudagraph_mode":"PIECEWISE"}, speculative_config={"method":"suffix","num_speculative_tokens":32} 이게 전부다. vanilla 대비 6개 워크로드 모두 +18.8%~+68.9% net-positive. 향상의 대부분은 사실 speculative decoding을 “켜는 것” 그 자체에서 나온다.
둘째, 이 설정은 무료가 아니다 — 아무 때나 켜면 느려진다. 7B 이하 모델은 무엇을 켜도 universal regression, code 워크로드에 ngram을 쓰면 −20% 회귀. 그래서 “켜느냐 마느냐”가 아니라 “언제 무엇을 켜느냐”가 핵심이고, 그 답은 R/K 부등식 하나로 mechanism까지 설명된다.
셋째, 모델 크기·워크로드 종류·모델 vendor가 모두 성패를 가른다. 14B 이상은 안전, Llama 70B는 6/6 net-positive지만 Qwen 72B는 code에서 회귀. §7의 decision tree가 그 경계를 정리한다.
측정 환경: Llama-3.3-70B-Instruct · TP=8 · H100×8 · vLLM speculative decoding (ngram / suffix). 9개 모델(opt-125m ~ Qwen 72B) × 6개 워크로드 × 설정 조합 156셀 측정 기반.