Uptime을 임대하던 부동산이 → tokens/watt를 생산하는 공장이 되었다
Classical IDC와 AIDC는 같은 단어 두 개로 묶이지만, 전력·냉각·네트워크·운영 KPI가 사실상 다른 운영 체계다 — 물론 현실에는 hyperscaler DC, GPU colo, neocloud, hybrid retrofit 같은 중간 형태가 공존한다. 그럼에도 부지 선정 기준에서부터 결제 단위까지 16개 레이어가 동시에 재정의되고 있다. 이 글은 L0(Site)부터 L15(Service)까지의 변환을 정량 데이터와 함께 한 페이지에 펼친다.
변환된 16개 레이어, 한눈에
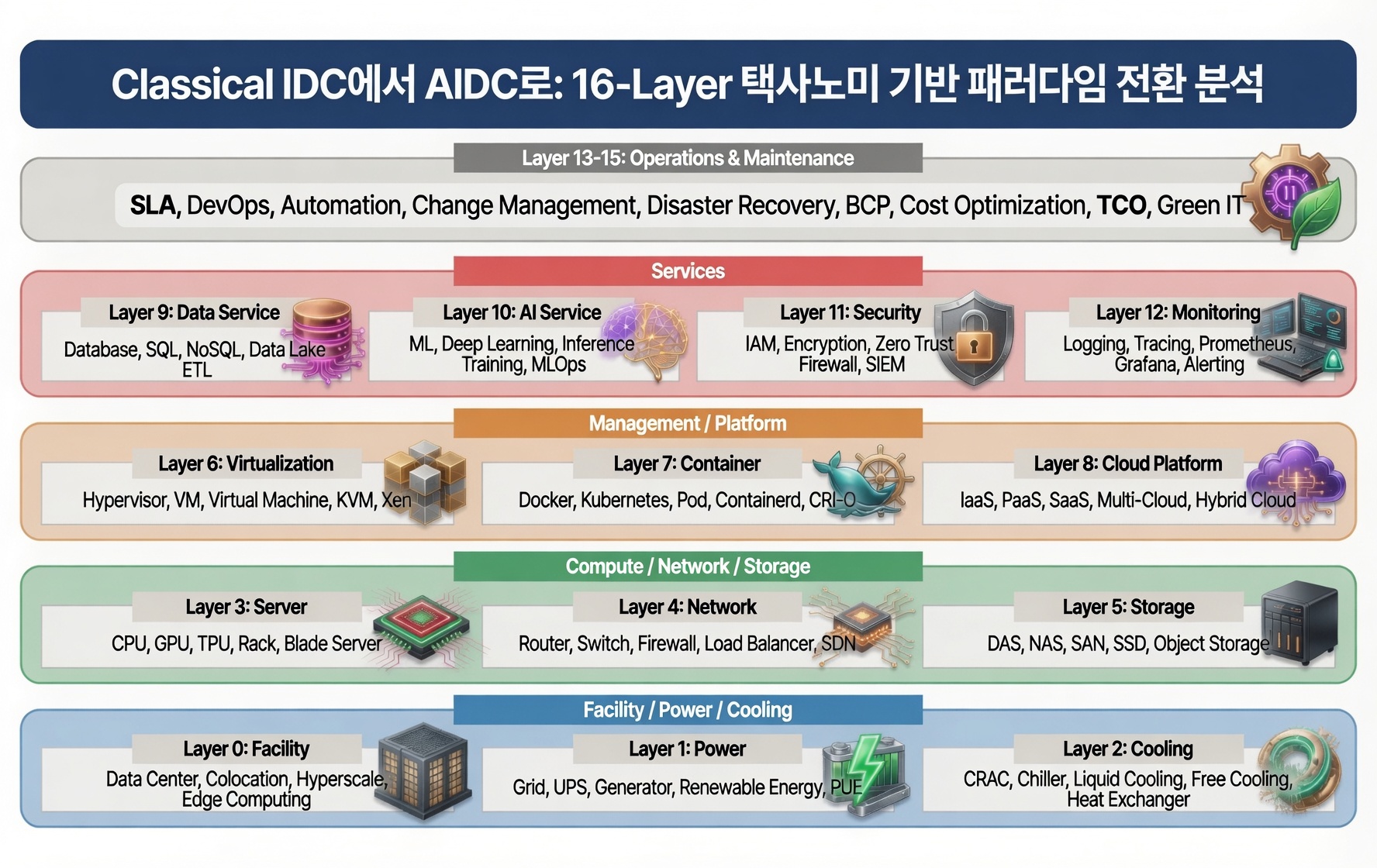
부지가 곧 전력이고, 건물이 곧 구조 보강이다
광 백본 + 도심 접근성에서 GW급 송전망 접근성으로. 부지 선정 기준이 뒤집힌 첫 번째 레이어.
Site Selection · Power Grid Interconnection · Building Structure · Floor Loading · Seismic Design · Tier Classification · Modular/Prefab DC · AI Factory · AI Campus
Classical IDC가 광 백본과 도심 접근성을 1순위로 두던 시대에, AIDC는 GW급 송전망 접근성, 대규모 수자원, 토지의 풍부함이 결정 요인이 되었다. 단위 MW당 면적도 1,500–3,000 m²(전통)에서 500–1,500 m²(수냉)로 줄지만, 전기실·CDU실·BESS실 면적이 크게 늘어 총량은 비슷하거나 더 크다.
건물 구조에서 가장 충격적인 변화는 floor load다. 전통 raised-floor 500–1,000 kg/m²(7.2–12 kPa)였던 것이, GB200 NVL72 한 rack이 1,360 kg, CDU flooded 시 추가 3 ton이 더해져 800–2,500 kg/m² 슬래브 보강이 권장된다. Eaton의 Heavy-Duty SmartRack(2024.10)은 static 5,000 lb(2,268 kg)로 설계되었다. 기존 IDC retrofit 시 hairline crack, pedestal deflection이 보고되는 이유다.
Tier Classification의 적용 방식도 변했다. 금융·국방용 Tier IV가 최상위였던 시대에, AIDC 학습 클러스터는 application-layer redundancy(checkpoint/restart)와 결합된 Tier III가 사실상 표준이다. Google Cloud는 Tier 자체를 사용하지 않는다고 명시한다 — facility 2N redundancy보다 분산 SW redundancy가 비용 대비 효과적이다.
Modular/Prefab DC는 더 이상 옵션이 아니다. Schneider EcoStruxure Pod Data Centre는 pod당 최대 1 MW+, 42 racks까지 100 kW+ rack을 수용하며, 공장 조립 후 현장 16주(전통 36주 대비 30% 단축)에 deploy된다. Vertiv SmartMod도 95% factory-tested로 14주 미만 출하한다.
5 kW에서 1 MW까지, 두 자릿수 도약
GPU TDP의 폭증이 전체 전력 인프라를 재구조화했다. 800V HVDC, BESS, SMR이 모두 등장한 이유다.
Grid Connection (154/345 kV) · 800V HVDC · BESS · UPS Li-ion · SMR · Fuel Cell · PUE/pPUE · Power Capping · Stranded Power · RE100/PPA/REC
Rack 전력 밀도는 인과 사슬의 출발점이다. GPU TDP가 A100 400W → H100 700W → B200 1,000W → Rubin Ultra 2,300W+ → Feynman(2028 추정) 4,400W로 증가하면서, rack 밀도가 폭증했다.
| 세대 | Rack Power | Power Distribution | UPS 전략 | 시기 |
|---|---|---|---|---|
| Classical IDC | 5–10 kW | 3φ 415/480V AC + 48V busbar | Double-conv + VRLA | ~2010–2022 |
| H100 era | 30–80 kW | 415/480V AC + 48V DC busway | Li-ion + supercap | 2023–2024 |
| GB200 NVL72 | 120 kW | 415V AC + 48V busbar | Li-ion + BBU | 2025 양산 |
| GB300 Blackwell Ultra | ~140 kW | 진화 중 (±400V 사이드카) | BBU 표준화 | 2025–2026 |
| Rubin Ultra / Kyber rack | ~600 kW 추정 (NVL576 기준) | 800 VDC 생태계 (OCP Diablo 400 기반) | OCP HPR + Flywheel | 2027 양산 목표 |
800VDC/±400VDC rack power architecture는 2027년 이후 고밀도 AI rack의 유력한 방향으로 부상하고 있다. 기존 54V DC busbar로 1 MW급을 분배하면 rack당 200 kg의 동(銅) busbar가 필요하고, 차세대 rack에서 최대 64U를 점유해 compute 공간이 사실상 없어진다. OCP Mt. Diablo (Diablo 400) 사양(2025.5 v0.5.2, Microsoft·Meta·Google 공동 저자, 2026.2 v0.7로 업데이트)은 사이드카 아키텍처로 AC→±400 VDC 수직 busbar를 구성하며, OCP 공식 표현으로는 “future fundamental base가 되기를 기대“하는 사양으로 100 kW에서 1 MW까지 확장 가능하도록 설계되었다 — 즉 산업 표준이 확정된 것은 아니고, 하이퍼스케일러 주도의 spec proposal 단계다. Schneider는 end-to-end 효율 +5%, 유지보수 −70%를 추정한다(벤더 자체 평가).
UPS도 다층화되었다. AI workload는 수천 GPU가 밀리초 단위로 동기 ramp해 시설 총 용량의 2–10%가 초 단위 스파이크된다 — 디젤 generator의 10–15초 startup으로는 대응 불가능하다. 해법은 chip/rack BBU(μs–ms) → Li-ion UPS(<10 ms) → grid BESS(100 ms) → generator(10–15 s)의 계층화다. xAI Colossus는 168× Tesla Megapack으로 ramp를 흡수한다. BESS 가격은 1991 $7,500/kWh → 2024 $133/kWh → 2030E $80/kWh로 급락 중이다.
PUE의 한계가 드러났다. Classical IDC PUE 1.5–1.8, hyperscaler 1.1–1.2, AIDC + D2C 수냉은 1.05–1.15까지 떨어졌다. 하지만 PUE는 시설 overhead 비율일 뿐 절대 효율이 아니다. Schneider Electric은 PCE(Power Compute Effectiveness)를 새로운 보완 KPI로 제안했다 — “provisioned power 중 얼마나 실제 유용한 compute work로 전환되는가”를 본다. 그 위에서 tokens/watt(unit energy당 AI 산출)와 cost/token(revenue 변환 효율)이 outcome-based 보완 지표로 자리잡고 있다.
On-site Generation은 선택이 아니라 필수가 되고 있다. 미국 behind-the-meter 데이터센터 파이프라인이 ~50 GW에 달한다. xAI Colossus Memphis는 portable gas turbine 35–46대(합산 422 MW)를 운용, Microsoft-Constellation Three Mile Island 837 MW 재가동(2028), Amazon-Talen Susquehanna 1,920 MW, Meta-Oklo 1.2 GW, Google-Kairos 500 MW SMR fleet 등 원전 르네상스가 가속화되고 있다. SMR 파이프라인은 2024년 말 25 GW → 2025년 말 45 GW로 늘었다(IEA).
한국 시사점: KEPCO 부채 202조원 초과로 송전 인프라 투자 지연, 동해안~신가평 갈등 등 신규 송전선로 건설 난항, 계통영향평가제도 도입으로 평가 통과해야 신규 DC 설립 가능. 국내에서도 KEPCO 주도의 LVDC 파일럿(2025.4)이 진행 중이며, 800V HVDC 흐름과 정합한다.
100kW+ rack에서 수냉이 새로운 baseline
GB200 GPU die heat flux는 공랭 한계의 40–100배. 100kW+ 고밀도 rack에서는 D2C 수냉이 baseline으로 이동 중이다 — 저밀도 추론·일부 retrofit 환경에서는 공랭·하이브리드도 여전히 쓰인다.
D2C (Direct-to-Chip) · Cold Plate · Immersion (Single/Two-phase) · RDHx · CDU · FWS/TCS Loop · Dry Cooler · WUE · Free Cooling · Waste Heat Reuse
공랭의 물리적 한계는 명확하다 — well-engineered hot/cold aisle containment 시 30–40 kW/rack이 상한이며, JLL은 41.3 kW/rack을 한계점으로 본다. GB200 GPU의 die heat flux는 500–600 W/cm²로 공랭 한계(5–15 W/cm²)의 40–100배다. 120 kW rack을 공랭 시도 시 팬 전력만 rack power의 20–30%를 소비하며 90+ dB 소음이 발생한다.
GB200 NVL72는 100% 수냉, 팬이 없다. 시설 chilled water 25–45°C 공급으로 120 kW 연속 방열한다. Cold plate는 열저항 ≤0.03 °C/W, 1.2 LPM/kW @ 45°C inlet, 6 bar 운전 / 12 bar burst 스펙이다. CDU(Coolant Distribution Unit)는 NVL72용 150–200 kW급이 표준이며, Google Deschutes CDU(OCP 2025)는 2 MW heat load, 500 GPM으로 업계 최고 사양이다.
| 기술 | Rack 한계 | PUE | WUE | 비고 |
|---|---|---|---|---|
| Standard CRAC | 8–12 kW | 1.5–1.8 | 1.5–2.0 L/kWh | Classical IDC |
| Containment | 15–25 kW | 1.3–1.5 | 동일 | retrofit |
| RDHx (active) | 30–120 kW | 1.2 | 감소 | hybrid 단계 |
| D2C 단상 (NVL72 표준) | 100–175 kW | 1.05–1.15 | ~0 (폐쇄루프) | 신규 표준 |
| D2C 이상 | 250–400+ | 1.05–1.10 | ~0 | Rubin 대비 |
| 단상 침지 | 100–150 kW | 1.02–1.10 | ~0 | 광유계 dielectric |
| 이상 침지 | 150–250+ | 1.01–1.03 | ~0 | PFAS 규제 이슈 |
더 큰 게임체인저는 Vera Rubin의 45°C 수냉 지원(CES 2026 발표) — Dry Cooler로 ambient air에 방열 가능, 기계식 chiller·Cooling Tower 불필요다. Microsoft는 2024년 8월 이후 신규 설계부터 closed-loop zero-water evaporation을 적용하며, Phoenix·Mt. Pleasant 파일럿이 2026년 가동, 본격 fleet 전환은 2027년 말부터이다 — 즉 기존 fleet는 여전히 air·water 혼합이며, “WUE ~0″은 신규 설계 IT loop 기준이다.
Waste Heat Reuse의 경제성도 부상한다. 수냉 outlet 50–60°C는 공랭 25–47°C 대비 폐열회수에 적합하다. Stockholm Data Parks는 30+ DC, 10,000호/800,000 m² 난방을 공급하며, 독일 EnEfG는 2026년 신규 DC 폐열 10%, 2028년 20% 의무화를 적용한다. ERE(Energy Reuse Effectiveness) 0.3–0.5가 신규 KPI다. 신규 AIDC 입지에서 인접 산업단지·신도시와의 지역난방 연계는 향후 규제 대비 사전 plumbing 설계의 가치가 있다.
1U 서버에서 NVL72 rack-scale 단일 GPU 도메인으로
72 GPU + 36 Grace CPU가 130 TB/s bisection으로 묶여 사실상 하나의 거대 GPU가 된다.
GPU (H100/H200/B200/GB200/Rubin) · Accelerators (TPU/Trainium/Gaudi/Groq/Cerebras/FuriosaAI) · CPU (Grace/EPYC/Xeon/ARM) · DPU/IPU (BlueField/Pensando) · Form Factor (HGX/MGX/DGX/OCP) · Rack-Scale (NVL72) · HBM3/HBM4/CXL · Heterogeneous (Ninja Gap)
Classical IDC의 dual-socket 1U/2U Xeon/EPYC 서버(서버당 300–800 W, DDR5 DRAM 수백 GB/s)는 AIDC에서 rack 단위 통합 GPU 도메인으로 진화했다. HGX(NVIDIA 8-GPU 모듈), MGX(modular reference), DGX(자체 시스템), OCP Open Rack v3가 standard form factor로 자리잡았다.
NVL72는 72 GPU + 36 Grace CPU를 5세대 NVLink/NVSwitch로 130 TB/s 집계 bisection bandwidth로 묶어, 사실상 하나의 거대 GPU로 동작하게 한다. 통합 HBM3e 메모리 풀 13.5 TB가 671B 파라미터 모델(DeepSeek R1) 전체를 단일 rack에 적재한다. NVIDIA 공식 발표 수치로 HGX H100 IB 대비 GPT-MoE 1.8T 학습 4×, 추론 30×, 에너지 효율 25×를 주장한다(벤더 자체 벤치마크 기준이며 독립 검증은 제한적).
| 모델 | HBM | BW | TDP | FP4/FP8 |
|---|---|---|---|---|
| H100 SXM | 80 GB HBM3 | 3.35 TB/s | 700 W | FP8 1,979 TFLOPS |
| H200 | 141 GB HBM3e | 4.8 TB/s | 700 W | +1.4–1.9× 추론 |
| B200 | 192 GB | 8.0 TB/s | 1,000 W | FP4 9,000 TFLOPS |
| GB200 NVL72 | 13.5 TB/rack | 576 TB/s | 120 kW/rack | FP4 1.44 EF |
| GB300 NVL72 | 20.7 TB/rack | 상향 | ~140 kW | 상향 |
| Vera Rubin NVL72 (H2 2026) | 288 GB HBM4/GPU | 1.6 PB/s/rack | — | 학습 2.5 EF/rack |
| Rubin Ultra Kyber (2027) | 1 TB HBM4e | — | ~600 kW/rack (NVL576 기준) | NVL144 단일 rack / NVL576 multi-rack 옵션 |
| AMD MI355X (2025.10) | 288 GB HBM3e | 8 TB/s | 1,400 W | FP4 20+ PFLOPS |
대안 Accelerator 생태계도 다양화되었다: Google TPU v5p/Trillium(Pathways), AWS Trainium2/Inferentia2, Intel Gaudi3, Groq(LPU, 추론 700+ tok/s), Cerebras(WSE-3, 1 chip = 1 wafer), SambaNova(RDU). 한국은 FuriosaAI RNGD(2024.8 발표, 추론 효율 NVIDIA 대비 +2.25× 주장)와 Rebellions ATOM-Max가 NPU 진영에서 부상 중이다.
DPU/IPU는 새로운 필수 컴포넌트가 되었다. NVIDIA BlueField-3(400 Gbps DPU, ARM 16-core), AMD Pensando가 host CPU에서 네트워크·스토리지·보안 처리를 offload하여 GPU 효율을 극대화한다. Heterogeneous Compute — “Ninja Gap”(CPU+GPU 하이브리드 추론에서 GPU-only를 능가하는 영역)이 추론 단계에서 본격 자리잡았다. Intel AMX/AVX-512 + GPU disaggregation은 Mooncake/DistServe 아키텍처와 결합된다.
North-South 80%에서 East-West 95%로
트래픽 패턴이 뒤집혔다. AIDC의 76%가 east-west, 단일 학습 잡이 수십 TB의 GPU-to-GPU 트래픽을 생성한다.
NVLink/NVSwitch · InfiniBand NDR/XDR · RoCEv2 · Ultra Ethernet (UEC) · UALink · Rail-optimized Fat-tree · Spectrum-X · SHARP · 800G/1.6T Optics · CPO · LPO · DCQCN/PFC/ECN
NVIDIA UFM · Cumulus/SONiC/FRR · BGP-EVPN · Multus · SR-IOV CNI · RDMA CNI · Cilium eBPF · Service Mesh (Istio/Ambient) · NCCL/RCCL/libfabric/UCX
트래픽 패턴이 뒤집혔다. Akamai/Data Center Frontier에 따르면 AIDC의 76% (분석에 따라 70–95%)가 east-west다. 단일 학습 작업이 수십 TB의 E-W 트래픽을 생성한다. 통신 패턴도 비동기적 RPC에서 결정론적·동기화된 collective(AllReduce, AllGather, ReduceScatter, All-to-All)로 바뀌었다. 그 결과 AIDC는 Frontend(관리·스토리지·외부)와 Backend(GPU compute fabric)를 물리적으로 분리한다.
- 10/25/100 GbE Top-of-Rack
- Tomahawk 3/4 (12.8–25.6 Tbps)
- ms급 latency 허용
- TCP/ECN congestion
- Calico/Flannel CNI
- 외부 사용자 트래픽 중심
- 400G NDR / 800G XDR, 1.6T 임박
- Quantum-X800 115.2 Tbps
- sub-microsecond / <100 ns port-to-port
- DCQCN + PFC + ECN tuning, HPCC
- Multus + SR-IOV + RDMA CNI, Cilium eBPF
- GPU collective 중심
Scale-up vs Scale-out 구분이 산업 표준이 되었다. Scale-up은 intra-rack/pod에서 메모리 시맨틱과 NVLink(5세대 1.8 TB/s/GPU)·NVSwitch·AMD Infinity Fabric으로 처리하고, Scale-out은 inter-rack에서 InfiniBand 또는 lossless Ethernet으로 처리한다.
개방형 표준이 본격 등장한 2025년은 분수령이다. UEC(Ultra Ethernet Consortium) 1.0(2025.6.11, 562쪽 사양)은 UET 전송 프로토콜, native RDMA, AI-tuned congestion control, 100만 endpoint 확장을 정의한다. UALink 1.0(2025.4)은 scale-up용으로 pod당 최대 1,024 accelerator, 819.2 TB/s 총 bidirectional을 지원한다.
Optics는 800G QSFP-DD/OSFP pluggable(9–15W/port)에서 1.6T OSFP를 거쳐 CPO(Co-Packaged Optics)·LPO(Linear Pluggable Optics)로 진화한다. NVIDIA Quantum-X Photonics(Q3450-LD, 144×800G)는 insertion loss 22 dB → 4 dB, 전력효율 5×, 복원력 10×를 달성한다.
SAN/NAS에서 TB/s parallel FS + GPU direct I/O로
$30k GPU가 IO 대기로 idle하는 비용을 막기 위해, 데이터 경로 자체가 CPU를 우회한다.
Lustre/GPFS/BeeGFS/WekaFS/VAST/DDN · DAOS · Ceph (RBD/CephFS/RGW) · MinIO/SeaweedFS · Rook/OpenEBS/Longhorn/Portworx · GPUDirect Storage (GDS) · NVMe-oF/NVMe/TCP · Alluxio/JuiceFS/Fluid · CheckFreq/Gemini
| 구분 | Classical IDC | AIDC |
|---|---|---|
| 프로토콜 | SAN(FC 16/32G), NAS(NFSv3/SMB) | Parallel FS (Lustre/GPFS/WekaFS/VAST), NFSoRDMA |
| 처리량 | 어레이당 수백 MB/s ~ 수 GB/s | rack당 수 TB/s, cluster 수십 TB/s |
| Latency | ms급 | μs급 (NVMe-oF) |
| 데이터 경로 | App → CPU → DRAM → NIC → Storage | GPUDirect Storage (GDS): GPU mem ↔ NVMe/NIC 직결 |
| 최적화 단위 | $/GB | $/(GB/s) + GPU idle 회피 |
| Caching | 별도 솔루션 | Alluxio, JuiceFS, Fluid (K8s 통합) |
Checkpoint 요구사항이 새로운 핵심 워크로드다. MLPerf Storage v2.0에 따르면 100k accelerator 클러스터는 1.5분마다 15 TB writeout, 일일 14 PB write, sync 시 cluster 평균 3.6 TB/s burst가 필요하다. 반면 VAST Data의 85,000 checkpoint 실측 분석은 async checkpoint로 ~845 GB/s도 가능함을 보여준다 — 양 수치는 동기/비동기 방식 차이로 양립한다.
구체적 수치: NVIDIA Eos는 DDN EXAScaler로 576 DGX H100에 4 TB/s, 12 PB / <3 rack을 공급한다. DDN AI400X2 + Spectrum-X는 rack당 2.4 TB/s read. GPUDirect Storage는 GPU 메모리에 40+ GB/s 직접 전송한다.
VM에서 MIG · Gang Scheduling · Disaggregated Inference로
VMware/OpenStack 스택은 GPU Operator + MIG + HPC 스케줄러로 대체되었다. 멀티테넌시 복잡도가 한 차원 증가했다.
K8s (Vanilla/OpenShift) · Slurm · Volcano (CNCF) · Kueue · Ray/KubeRay · GPU Operator · MIG · MPS · HAMi · Run:ai · Gang Scheduling · Topology-aware · Resource Governance (Commons)
7.1 — GPU 자원 격리: MIG + Gang Scheduling
MIG(Multi-Instance GPU)는 H100에서 최대 7 compute slice + 8 memory slice로 19개 프로파일 지원, HW 격리로 vGPU(SW 격리) 대비 enterprise-grade noisy-neighbor 차단을 제공한다. MIG + time-slicing 조합 시 단일 GPU에 최대 28(=7×4) 리소스 요청 서빙 가능. K8s 1.31+ DRA(Dynamic Resource Allocation)는 MIG 동적 재분할을 가능케 한다.
vanilla K8s nvidia.com/gpu: 1은 GPU 전체를 점유한다. 단일 잡이 1,024 GPU에 걸쳐있을 때 일반 스케줄러는 partial allocation으로 시작 → 1,024장 동시 확보 실패 시 GPU deadlock → gang scheduling이 필수가 된다.
NCCL AllReduce는 ring/tree topology를 가정하므로 스케줄러가 NVLink 도메인을 무시하면 throughput 50%+ 손실이다.
| 항목 | vanilla K8s | Volcano | Slurm | Ray/KubeRay | Kueue |
|---|---|---|---|---|---|
| Gang scheduling | ❌ (deadlock) | ✅ | ✅ native | ✅ (Volcano) | ✅ |
| Topology-aware | ❌ | ✅ | ✅ | △ | △ |
| 처리량 | baseline | 2–4× vs K8s | μs batch | 워크플로 | hierarchical quota |
FSDP · DeepSpeed ZeRO · Megatron-LM · Colossal-AI · DP/TP/PP/EP/SP · BF16/FP8/FP4 · Activation Checkpointing · NCCL/SHARP/Overlap · Elastic Training · W&B/MLflow
vLLM · TensorRT-LLM · SGLang · llm-d · Triton · KServe · Ray Serve · NVIDIA Dynamo · Prefill-Decode Disaggregation · PagedAttention/RadixAttention/LMCache · EAGLE-3/MTP · AWQ/GPTQ/SmoothQuant · DeepEP/DeepGEMM · Multi-LoRA · LiteLLM/Portkey
7.2 — Inference: PD Disaggregation의 시대
NVIDIA Dynamo의 차별점: prefill(compute-bound)과 decode(memory-bound)를 분리된 GPU pool에 disaggregated serving한다. SLA-based Planner가 TTFT/ITL 목표 입력 시 자동 prefill/decode worker 스케일링, KV-aware routing, HBM → CPU mem → NVMe → S3/Azure blob 계층적 KV offload. GB200 NVL72에서 DeepSeek-R1 +30× vs 기존, MoE +50× vs Hopper를 NVIDIA가 발표했다(독립 검증 제한적).
MoE Inference는 별도 최적화 도메인이다 — DeepEP(expert routing), DeepGEMM(FP8 grouped GEMM), Expert Parallelism 매핑이 핵심이다. Multi-LoRA Serving(수천 어댑터 동시 서빙)과 Adapter Routing(LoRAX, PEFT)이 mass customization을 가능케 한다. Inference Gateway(LiteLLM Proxy, Portkey, Kong AI)는 multi-model routing·rate limit·캐싱을 통합한다.
LangGraph · AutoGen · CrewAI · OpenAI Agents SDK · MCP (Model Context Protocol) · Temporal/Restate · E2B/Daytona/Modal · Kafka/Pulsar · Delta/Iceberg/Hudi · Spark/Ray Data/Flink · Data Mesh/Contracts · DataHub/Atlan
7.3 — Agent Layer와 Data Platform
Agent Layer (L7.5)는 새로 추가된 도메인이다. LangGraph, AutoGen, CrewAI, OpenAI Agents SDK가 agent framework, MCP(Model Context Protocol)가 tool integration 표준이며, E2B/Daytona/Modal이 sandbox/code execution을 담당한다. Temporal/Restate가 long-running agent workflow를 담당한다.
Data Platform (L8): 전통 IDC가 RDBMS + Oracle Exadata + DataStage ETL이었다면, AIDC의 데이터 평면은 Lakehouse(Delta/Iceberg/Hudi) + Streaming(Kafka) + Distributed Compute(Spark/Ray Data) + Catalog(DataHub/Unity)가 표준이다. LLM 학습 데이터는 PB급 텍스트의 Distributed Tokenization + Deduplication(MinHash, SimHash)가 별도 워크로드를 형성한다.
Stateless ms 작업에서 동기화된 수개월 학습으로
Meta Llama 3.1 405B 54일 학습 실측 — 3시간당 1회 인터럽트. 분산 신뢰성이 별도 R&D 영역이 된 이유다.
Meta Llama 3.1 405B 실측(2024, 16,384 H100, 54일 pre-training)이 결정적 데이터다. 총 인터럽트 466건 = 계획 47 + 예상치 못한 419건, 평균 3시간당 1회. 실패 원인은 GPU 30.1% + HBM3 17.2% + 네트워크 8.4% + SRAM 4.5% + GPU 시스템 프로세서 4.1%로 GPU/HBM이 unplanned의 약 58.7%를 차지한다. 419건 중 3건만 human intervention 필요 — async checkpoint + NCCL flight recorder로 effective training time >90% 유지. CPU 장애는 단 2건(0.5%)에 불과했다 — Classical IDC와 정반대 분포다.
100K GPU로 외삽 시 ~30분당 1회 fail 가능성. xAI Colossus 555,000 GPU급(SemiAnalysis 등 보도 추정)에서는 분산 신뢰성 공학이 별도 R&D 영역이다.
새로운 KPI들
MFU(Model FLOPs Utilization)가 새로운 KPI다. H100 BF16 이론치 989 TFLOPS 대비 Llama 3.1 405B는 38–43% 달성, PaLM은 ~46%, FP8 MoE는 ~20%. 양호 기준은 40–50% sustained다. 학습 총 비용: Llama 3.1 405B = 30.84M GPU-hours, ~21.6 GWh, ~8,930 tCO2eq.
전력 패턴 — Grid Stress
AllReduce 동기화는 compute(700W) ↔ communication(저전력) square-wave를 생성, 16K–100K GPU 동시 진동 시 랙·로우·DC 인입선까지 수십 MW 스윙(Oracle OCI 실측). arXiv 2508.14318은 GPU가 서버 provisioned power의 >50%를 점유하며 oscillation 주파수가 grid resonance와 일치 시 물리적 손상 우려를 보고한다.
- Stateless web/DB, ms~min
- 독립적, 60–70% flat load
- dP/dt 작음
- 일반 UPS로 대응
- SLA: uptime 99.9%, p99 latency
- 분산 training, 수일~수개월
- 1K–100K GPU, AllReduce 지배적
- 30–95% in seconds, dP/dt 수십 MW/s
- GPU power smoothing, bi-way UPS, dummy workload
- Training: MFU, Goodput, JCT · Inference: TTFT, ITL, TPOT
5분 SNMP에서 1초 DCGM + Digital Twin으로
텔레메트리 sampling 주기가 300배 빨라졌고, Digital Twin이 표준 운영 도구가 되었다.
Prometheus/Thanos/Mimir/VictoriaMetrics · Loki/OpenSearch/Vector · Tempo/Jaeger/OpenTelemetry · Pixie/Parca/Coroot (eBPF) · DCGM/Nsight Systems · PyTorch Profiler/HTA · Schneider EcoStruxure/Vertiv/Sunbird · NVIDIA Omniverse/Cadence Reality DC · Anomaly Detection/Predictive Maintenance/Causal RCA
DCIM은 Schneider EcoStruxure IT, Vertiv Trellis, Sunbird(SNMP/Modbus/BACnet 5분 polling)에서 AI-era DCIM + NVIDIA Mission Control + Omniverse Digital Twin으로 진화했다.
NVIDIA DCGM + DCGM-Exporter는 sub-second polling(보통 1s, classical 5분 대비 300배)으로 SM 활용률, HBM 온도, NVLink CRC/replay, ECC SBE/DBE, PCIe replay 등 GPU당 500+ metric을 수집한다. XID error가 워크로드 실패 전에 metric으로 나타나 예측 정비를 가능케 한다.
| 레이어 | Classical | AIDC |
|---|---|---|
| Metrics | Zabbix/Nagios/Cacti | Prometheus + Thanos/Mimir + VictoriaMetrics |
| Logs | rsyslog → ELK | Loki/OpenSearch + Vector pipeline |
| Traces | (별로 없음) | OpenTelemetry + Tempo/Jaeger |
| eBPF | N/A | Pixie/Parca/Coroot (커널 무중단 관찰) |
| GPU | N/A | DCGM + Nsight + PyTorch Profiler + HTA |
Digital Twin이 본격화되었다
Cadence Reality DC Platform + NVIDIA Omniverse DSX blueprint는 14,000+ 부품 / 750+ vendor 라이브러리, GB200 NVL72 모델 포함, mechanical/thermal(CFD)/fluid dynamics/electrical 통합 시뮬레이션을 제공한다. Cadence 공식 성과: 워크플로 30× 가속, 에너지 효율 30% 개선. NVIDIA가 자사 슈퍼컴 설계에 직접 사용한다.
AIOps는 단순 모니터링을 넘어선다 — Robust PCA·Isolation Forest 기반 이상탐지로 HW failure를 24–72시간 사전 예측, Causal Inference로 RCA를 자동화, Capacity Planning(Forecasting)으로 GPU 수요 6개월 선행 예측, Self-healing Automation은 XID error 발생 시 자동 노드 drain + checkpoint resume까지 무인 처리한다.
Perimeter에서 Confidential Computing + Sovereign AI로
Data-in-use까지 보호하는 패러다임. Model IP는 수조원 자산이고, Sovereign AI는 국가 단위 경쟁이 되었다.
Keycloak/Okta/Azure AD · SPIFFE/SPIRE · Vault/External Secrets · Intel TDX/AMD SEV-SNP/ARM CCA · NVIDIA H100/H200 CC mode · Keylime/Veraison (Attestation) · FHE/MPC/DP (PPML) · SBOM/Sigstore/in-toto · Falco/Tetragon · OPA/Kyverno · NeMo Guardrails/LlamaGuard · C2PA
Classical IDC 보안은 물리(mantrap, biometric), 망분리(VLAN, DMZ, WAF), 컴플라이언스(ISO 27001, SOC 2, K-ISMS)로 perimeter 중심이다. 데이터 보호도 at-rest/in-transit만 보호되고 in-use는 평문으로 노출되었다.
AIDC는 Confidential Computing으로 data-in-use까지 보호한다. NVIDIA H100/H200/B200 CC mode는 on-die RoT 기반 CVM TEE를 구성, HBM VRAM·PCIe·NVLink까지 암호화한다. Intel TDX, AMD SEV-SNP, ARM CCA와 결합한 composite attestation을 통과해야 KMS가 모델 복호화 키를 TEE 내부로 release한다. 성능 overhead는 5–15%이며, hypervisor·CSP 운영자·물리 접근자조차 모델·데이터 접근 차단된다.
Model IP 보호가 새로운 도메인으로 등장했다. Frontier 모델 weight는 학습비용 $100M–$1B+의 수조원 IP다. OWASP LLM01:2025의 1위 취약점인 Prompt injection은 단일턴 공격 성공률 ~13%, 멀티턴은 평균 60%+, 일부 모델 92.78%(Cisco AI Defense 2025). arXiv 2511.15759 프레임워크(content filtering + hierarchical guardrails + multi-stage verification)는 공격 성공률 73.2% → 8.7%로 낮춘다.
Sovereign AI가 국가 단위 인프라 경쟁으로 부상했다. UAE G42(MS $1.5B), 프랑스 Mistral(€109B AI Action Summit), 미국 Stargate $500B, EU AI Act, 한국 NAICC(2조~2.5조원, 1+ EF, 2027~28). NVIDIA-한국 정부 2025년 발표는 총 260,000+ GPU(NAICC + NHN/Kakao/NAVER 50k + Samsung 50k + SK 50k + Hyundai 50k Blackwell)다.
1.5%에서 4%로, multi-GW 단지의 시대
글로벌 DC 전력이 +128% 증가한다. PUE 하나만으론 부족하고, WUE/CUE/ERE 4-metric 시대.
단지 규모의 질적 변화: 전통 IDC 10–50 MW vs hyperscaler 50–150 MW vs AIDC 100 MW – multi-GW. Meta Hyperion (Louisiana Richland Parish)은 Meta 공식 발표 기준 2GW+ compute capacity, 보도·Zuckerberg 발언으로는 장기적으로 5GW까지 확장 가능. AWS Susquehanna 1,920 MW. Stargate $500B/4년. xAI Colossus는 SemiAnalysis·Tom’s Hardware 등 보도에 따르면 약 555,000 GPU, 2 GW 규모(xAI 공식 단일 발표는 없으며, $18B는 추정치)로 알려져 있다.
| Metric | 정의 | Classical | Hyperscaler | AIDC 목표 |
|---|---|---|---|---|
| PUE | Total / IT Power | 1.5–1.8 | 1.1–1.2 (Google 1.09) | <1.3 (D2C) |
| WUE | Water / IT Energy | 1.8–2.0 L/kWh | 0.5–1.0 | 폐쇄루프 ~0 |
| CUE | CO2 / IT Energy | 그리드 의존 | 24/7 CFE 추구 | 무탄소 PPA·SMR |
| ERE | (Total − Reused) / IT | 0–0.1 | 0.2–0.3 | 지역난방 0.4+ |
한국 ESG 현실은 가혹하다
재생에너지 비중 ~10%(OECD 평균 1/3), RE100 가입 한국 183개사 중 70개사(38.3%)가 조달 어려움 호소(CDP 2024, 미국의 3.5배). PPA 부대비용(망사용료 + 전력산업기반기금)이 발전단가의 18–27%. 삼성전자 한국 재생에너지 비중 2.7%, NAVER PPA 5%. RE100 100% 달성은 사실상 불가능하다.
국내 AIDC ESG 전략: 100% RE 달성 대신 K-CFE(24/7 무탄소에너지, 원전 포함) + 국내 BESS + 향후 SMR 옵션 + ERE 0.3+ 조합이 현실적 differentiation이다. 인접 산업단지·신도시 지역난방 연계로 폐열 회수, 폐쇄 루프 수냉으로 WUE ~0 달성이 권장된다.
Per-Rack에서 Per-Token, GPU-backed Finance로
Pricing 단위 자체가 바뀌었다. GPU가 담보가 되고, 토큰이 결제 단위가 되었다.
Backstage/Port/Cortex (IDP) · JupyterHub/Hex/Deepnote · Claude Code/Cursor 통합 · Spec-Driven Development Infra · Coding Agent Infra · Self-Service Portal
GPU Cost Attribution · Showback/Chargeback · Spot/Preemptible · Token Economics · Reserved Capacity · Kubecost/OpenCost/CloudZero/Vantage
IaaS/CaaS/PaaS · MaaS · AaaS (Agent as a Service) · FaaS for AI · Sovereign Cloud · Neocloud (CoreWeave/Lambda)
| 차원 | Classical Colo | AIDC |
|---|---|---|
| 단위 | per rack-month / kW | per GPU-hour, per M token |
| H100 시세 | — | $1.45 (SF) ~ $6.16 (CoreWeave) ~ $11.06 (AWS) /hr |
| H100 1-yr reserved | — | $1.70/hr (2025.10) → $2.35/hr (2026.3), +40% |
| MaaS pricing | N/A | GPT-5.4 $2.50/$15, Claude Opus 4.5 $5/$25, Gemini 3 Flash $0.50/$3 per M tokens |
| Hyperscaler vs Neocloud | — | DGX H100 hyperscaler $98/hr vs neocloud $34/hr (66% 절감) |
Service Layer가 다층화되었다 — IaaS(bare-metal GPU/VM) → CaaS(K8s containers) → PaaS(ML platform) → MaaS(model API) → AaaS(agent runtime) → FaaS for AI(serverless inference, Replicate, Modal, Banana). 동일 GPU 자산이 여러 layer로 변환되어 monetization 다각화가 가능하다.
Internal Developer Platform (L13)도 새로 등장했다. Backstage(Spotify), Port, Cortex가 service catalog와 golden path를 제공, 개발자가 GPU quota request → job submission → cost showback까지 self-service로 처리한다. AI-native DevEx에서 JupyterHub/Hex/Deepnote가 데이터 사이언티스트 UX, Claude Code/Cursor 통합이 코딩 에이전트 인프라의 핵심이다. Spec-Driven Development Infra가 새로운 paradigm으로, AI 협업 개발에서 spec이 single source of truth가 된다.
Neocloud 모델(CoreWeave, Lambda, Crusoe, Nebius)이 등장했다. CoreWeave는 40+ DC, 250k+ GPU, OpenAI $11.9B 5년 계약, MS $10B+ 다년계약을 확보. 2026.3에 DDTL 4.0 $8.5B 조달(A3 등급, 최초 IG 등급 GPU-backed financing).
GPU as collateral이 새로운 금융 패턴이다. Lambda는 $500M GPU-backed ABS 업계 최초, NVIDIA가 Lambda 18k GPU $1.5B 리스백 — NVIDIA가 자체 ecosystem 자금 공급자가 되는 round-trip finance가 성립한다. Risk: H100 스팟 가격이 $7–10 → $2–4 in 18개월 하락 후 다시 +40% 반등하는 변동성.