
칩이 아니라 ‘공장’을 판다 — NVIDIA가 AI 팩토리 전체를 하나의 청사진으로 묶었다. · NVIDIA DSX 종합 분석
전력이 병목인 시대, 경쟁의 단위는 FLOPS가 아니라 ‘메가와트당 토큰’이다.
NVIDIA DSX는 단일 칩·서버 제품이 아니라 AI 팩토리 전체를 설계·시뮬레이션·구축·운영하기 위한 풀스택 플랫폼이자 레퍼런스 아키텍처다. 이 글은 네 개의 AI 리서치 리포트(Claude·Gemini·Grok·OpenAI)를 교차 검증해 정리한 종합본이다. 수치·명칭이 상충하거나 NVIDIA 공식 문서로 확인되지 않는 항목은 본문에 색 박스로 표시했다 — 의사결정 전 1차 출처 재검증을 권한다.
칩 경쟁에서 ‘메가와트당 토큰’으로
왜 데이터센터가 아니라 ‘공장’인가.
초거대 모델 시대의 데이터센터는 더 이상 정보를 저장·전송하는 수동적 인프라가 아니다. 원시 데이터와 전력을 입력받아 추론·예측을 토큰(token)이라는 지능으로 실시간 변환·생산하는 연속 제조 공정 — AI 팩토리다. 전력이 최대 제약이 되면서, 경쟁의 단위도 칩 성능에서 고정된 전력 예산으로 얼마나 많은 토큰을 뽑느냐(tokens per megawatt)로 옮겨갔다.
DSX의 철학은 ‘극단적 공동설계(Extreme Codesign)’다. 전력·냉각·컴퓨팅을 따로 조립하면 자원 유휴화와 열 진동이 필연이다. DSX는 칩·인터커넥트·스토리지·운영 소프트웨어는 물론 초고밀도 전력 공급과 액체 냉각까지 모든 계층을 처음부터 하나의 시스템으로 최적화한다.

DSX란 무엇인가
완제품이 아니라 ‘남이 짓는 AI 팩토리’를 위한 개방형 플레이북.
NVIDIA 공식 정의는 “NVIDIA’s AI factory-scale platform” — 설계·시뮬레이션·운영·생태계 기술을 묶어 최저 토큰 비용에 최적화된 AI 팩토리 구축을 돕는다. Jensen Huang의 표현을 빌리면, “한 푼 쓰기 전에 전체 팩토리를 시뮬레이션하고, 랙 한 대 설치 전에 성능을 검증하며, 프로덕션 신뢰성으로 운영”하게 하는 완전한 플레이북이다.
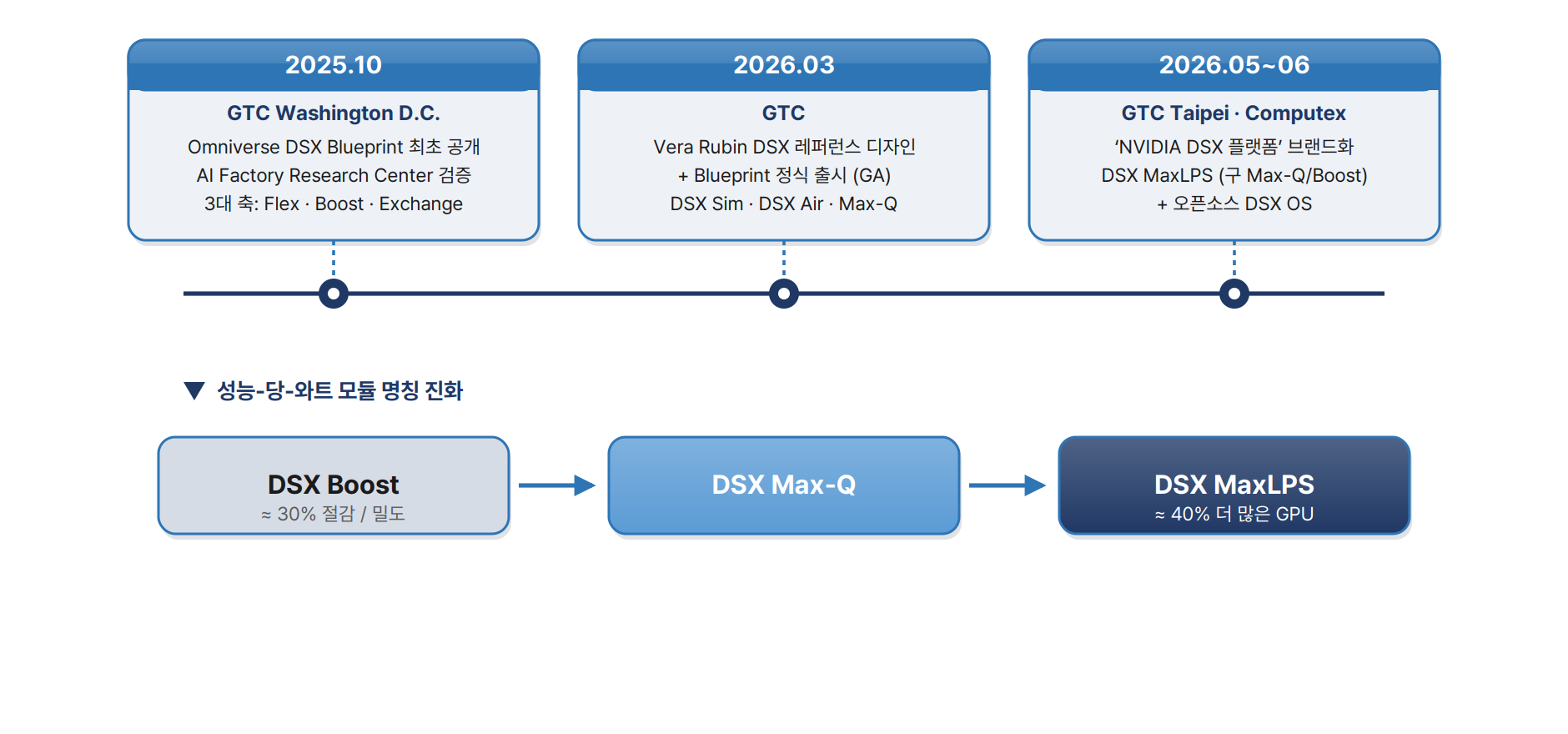
발표는 3단계로 진화했다 — 2025년 10월 GTC D.C.에서 Omniverse DSX Blueprint 최초 공개, 2026년 3월 GTC에서 Vera Rubin 레퍼런스 디자인과 Blueprint 정식 출시(GA), 2026년 5~6월 GTC Taipei/Computex에서 ‘DSX 플랫폼’ 브랜드화와 함께 DSX MaxLPS·오픈소스 DSX OS가 추가됐다.

6대 핵심 구성요소
설계 → 시뮬레이션 → 운영을 관통하는 여섯 축.
| 구성요소 | 역할 | 핵심 |
|---|---|---|
| ① DSX Reference Design | 세대별 검증 아키텍처 | 컴퓨팅·네트워크·스토리지·시설(전력·냉각)까지 end-to-end. 현 세대 = Vera Rubin DSX. |
| ② DSX Sim | 고충실도 디지털 트윈 | DSX Air(클라우드 논리) + Omniverse DSX Blueprint(OpenUSD 물리 트윈, GA). |
| ③ DSX OS | 모듈형 운영 SW (대부분 OSS) | NICo·AICR·NVSentinel·KAI·Dynamo·NVCF·Exchange는 오픈소스(Apache 2.0). Run:ai·NIM은 상용. |
| ④ DSX MaxLPS | 동적 전력·효율 SW | 45°C 액냉 + 인랙 기술로 동일 MW에서 최대 40% 더 많은 GPU 운영. |
| ⑤ DSX Flex | 전력망 연동 | 수요반응·부하차단·가격 신호 대응. BESS·재생에너지 하이브리드 제어. |
| ⑥ DSX Exchange | IT/OT 통합 패브릭 | MQTT/NATS 이벤트 버스 + MCP 서버로 AI 에이전트가 교차 도메인 상관. |
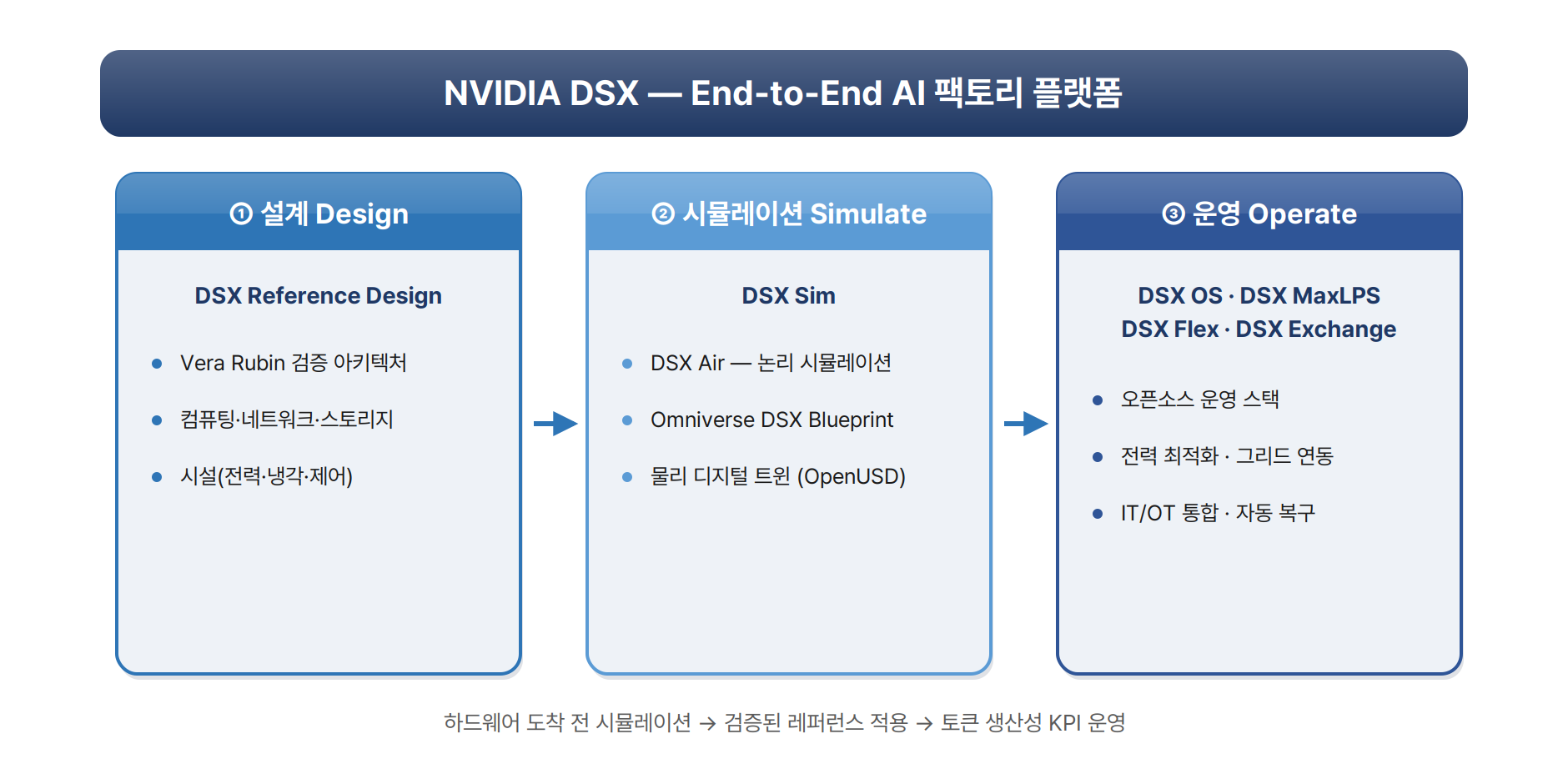
이 중 운영 계층의 심장은 DSX OS다. 단일 모놀리식 OS가 아니라, NVIDIA가 DGX Cloud에서 검증한 인프라/플랫폼 소프트웨어를 모듈 집합으로 외부화한 것 — 대부분 Apache 2.0 오픈소스라, 운영자는 전면 교체 없이 가장 시급한 영역부터(IT/OT 통합이면 Exchange, 베어메탈 격리면 NICo) 점진 채택할 수 있다.

HGX · MGX · DGX · POD · DSX는 어떻게 다른가
가장 자주 헷갈리는 NVIDIA 빌딩블록 계층.
DSX의 위치를 이해하려면 빌딩블록을 세워보면 된다. GPU(다이) → 보드·랙 빌딩블록(HGX/MGX, NVL72 랙) 위에서 랙을 묶는 방식이 두 갈래로 갈린다. (1) 동질 묶음 — 동일한 DGX 시스템을 Scalable Unit(SU) 배수로 반복해 DGX BasePOD/SuperPOD를 만든다. (2) 이질 묶음 — NVL72·Groq LPX·Vera CPU·STX·SPX 등 5종 특화 랙을 하나의 슈퍼컴퓨터로 묶어 Vera Rubin POD를 만든다. DSX는 이 중 이질 묶음(Vera Rubin POD)을 빌딩블록으로 삼는다 — DGX SuperPOD은 동질 클러스터의 별도 경로로 DSX 구성요소가 아니다. 즉 SuperPOD와 Vera Rubin POD는 같은 칸이 아니라, NVL72 랙을 위로 묶는 서로 다른 두 방식이다.
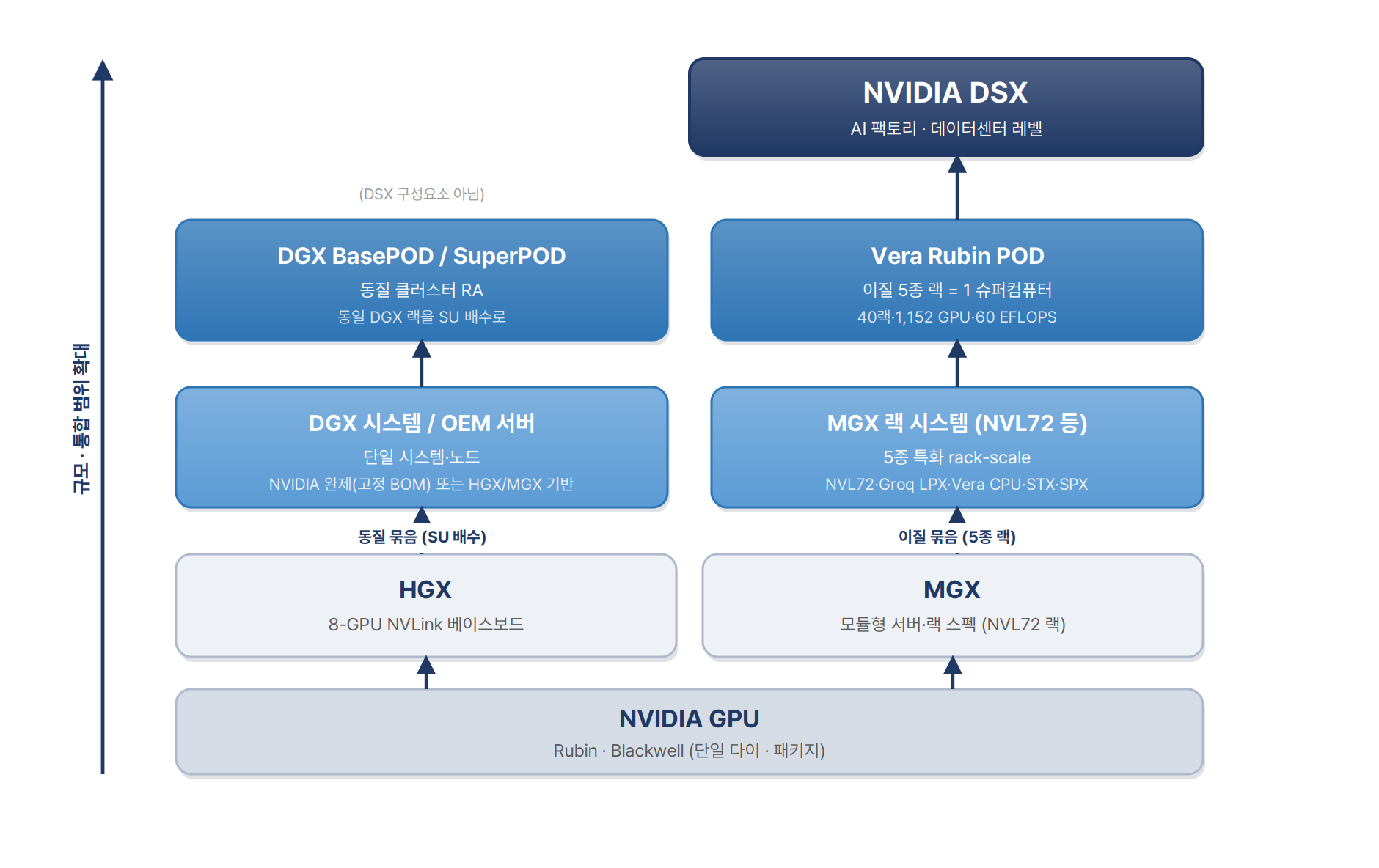
| 빌딩블록 | 정의·범위 | 규모 | 예시 |
|---|---|---|---|
| HGX | NVLink로 묶인 8-GPU 베이스보드. 최대 인터커넥트 학습 노드. | 보드(8 GPU) | HGX H100/B200 |
| MGX | 모듈형 서버·랙 사양. 100+ 구성, 다세대 호환. HGX의 상보(대체 아님). | 서버~랙 | MGX NVL72 랙 |
| DGX | HGX 기반 NVIDIA 자체 완제 시스템(고정 BOM)·직접 지원. | 시스템(노드) | DGX B300, GB200 |
| DGX BasePOD | 컴퓨팅·네트워크·스토리지·SW 통합 소규모 클러스터 RA. | 2~40 노드 | BasePOD RA |
| DGX SuperPOD | 동일 DGX 시스템을 SU 배수로 반복하는 동질 턴키 슈퍼컴 RA. Mission Control 운영. | 32~수천 노드 | GB200/B300 SuperPOD |
| Vera Rubin POD | 이질 5종 특화 랙(NVL72·Groq LPX·Vera CPU·STX·SPX)을 1 슈퍼컴퓨터로. 3세대 MGX 기반. | 40랙·1,152 GPU | Vera Rubin POD |
| DSX | AI 팩토리 스케일 플랫폼. 컴퓨팅 + 전력·냉각·그리드·시설·트윈·OS까지. | 100MW~GW급 | Vera Rubin DSX |
핵심 관계는 셋이다. 첫째, HGX와 MGX는 경쟁이 아니라 상보적이다 — HGX는 고대역폭 8-GPU 베이스보드, MGX는 추론·혼합 구성을 아우르는 유연한 랙 스펙(NVL72 랙이 MGX다). 둘째, DGX SuperPOD ≠ Vera Rubin POD — 같은 Vera Rubin NVL72 랙을 8랙씩 동일하게 묶으면 SuperPOD(동질·SU 배수), 5종 특화 랙으로 묶으면 Vera Rubin POD(이질)다. 같은 사다리 칸이 아니라 랙을 위로 묶는 다른 방식이다. 셋째, DSX는 그 위 데이터센터 레벨 — 전력·냉각·그리드·트윈·오픈 OS까지 포함해 제3자가 자체 AI 팩토리를 짓도록 하는 개방형 플랫폼이다.
Vera Rubin POD 하드웨어
7종 칩, 5종 랙, 하나의 슈퍼컴퓨터 — 그리고 이것은 DSX가 아니다.
먼저 용어를 정확히 하자. 아래 수치는 rack-scale 시스템인 Vera Rubin POD의 사양이지 DSX의 사양이 아니다 — DSX는 이 POD를 데이터센터·AI 팩토리 규모로 배치·운영하는 레퍼런스 디자인 레벨이고, POD는 그 안에 들어가는 빌딩블록이다(‘04’ 계층도 참조).
현 세대 POD는 7종 칩의 코디자인으로 구성된다 — 40개 랙, Rubin GPU 1,152개, 약 20,000개 다이, 1.2 quadrillion(1,200조) 트랜지스터, 60 엑사플롭스, 스케일업 대역폭 10 PB/s. 출하는 2026년 하반기. 5종 랙으로 매핑된다. (출처: NVIDIA Technical Blog — Vera Rubin POD)

| 랙 | 역할 |
|---|---|
| NVL72 | Rubin GPU 72 + Vera CPU 36. 학습·추론 핵심. NVFP4 3.6 EFLOPS. |
| Groq 3 LPX | LPU 256. 저지연 디코드 추론. |
| Vera CPU | CPU 256. RL·에이전트 오케스트레이션. |
| BlueField-4 STX | AI 네이티브 스토리지, CMX(KV 캐시) 계층. |
| Spectrum-6 SPX | 실리콘 포토닉스 이더넷 백본. |

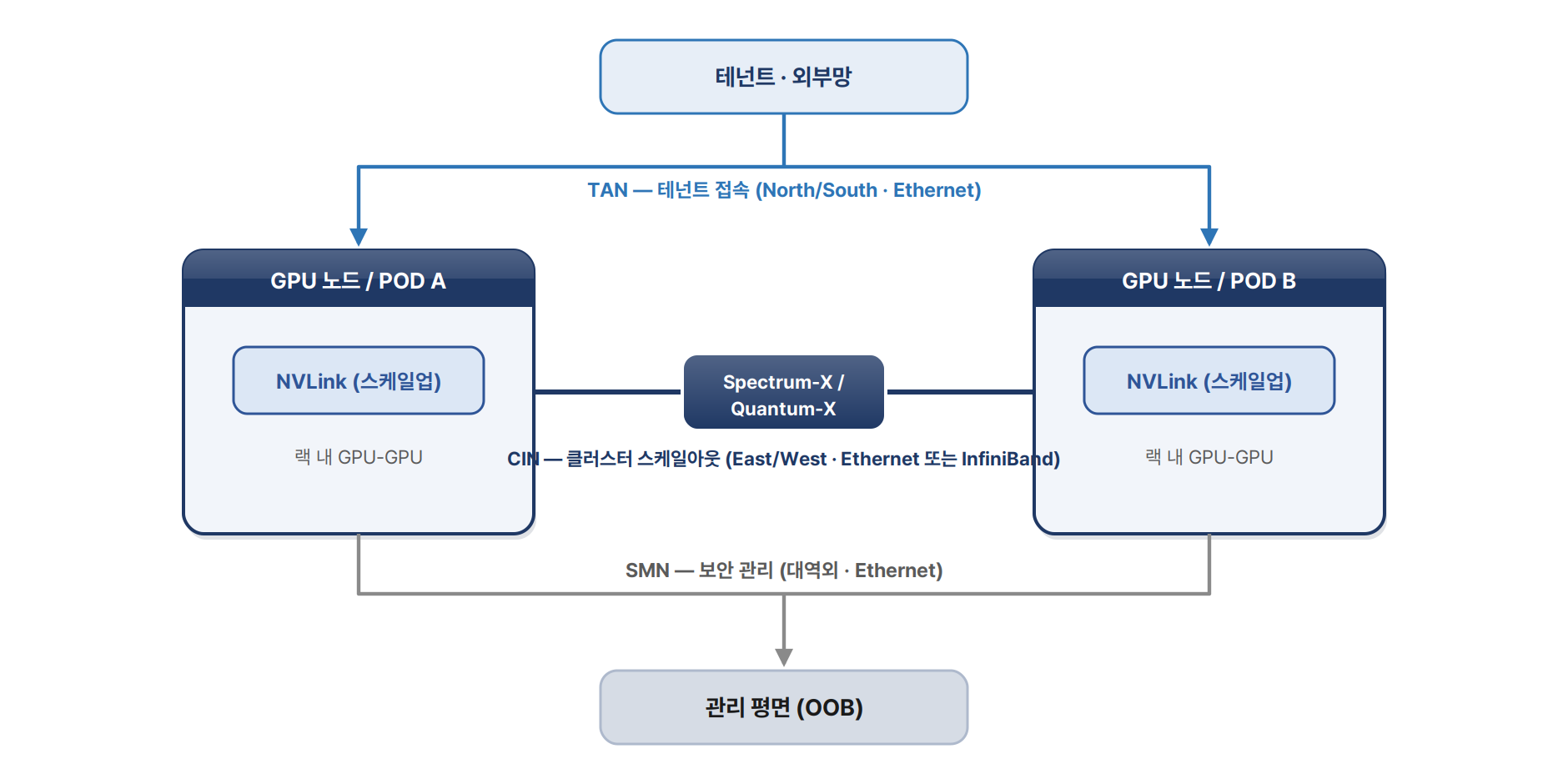
NCP Hardware Reference Design은 4종 네트워크 평면으로 구성된다 — TAN(테넌트 접속, N/S, Ethernet), CIN(클러스터 스케일아웃, E/W, Ethernet 또는 InfiniBand), NVLink(랙 내 스케일업), SMN(대역외 보안 관리). GPU POD를 최대 64개까지 묶어 약 73,728 GPU를 지원한다.
전력·냉각·800VDC
랙 전력이 120kW에서 600kW로 가는 길.
DSX는 공통 아키텍처로 100MW에서 멀티 기가와트까지 커버한다. 랙 전력 상승 곡선은 GB300 NVL72(Blackwell) 풀랙 142kW(공식)에서 Vera Rubin NVL72 약 120~130kW를 거쳐 Rubin Ultra Kyber 약 600kW(2027)로 향한다. 이를 감당하기 위해 전력 분배도 기존 54VDC/480VAC에서 800 VDC로 전환된다 — 구리 사용과 변환 손실을 줄여 엔드투엔드 효율 최대 5% 개선, TCO 최대 30% 절감을 NVIDIA는 제시한다(본격 양산은 2027년 Kyber와 함께).

디지털 트윈과 SimReady
랙 한 대 설치 전에 50에이커 팩토리를 통째로 시뮬레이션한다.
Omniverse DSX Blueprint(GA)는 50에이커(약 6만 평) 부지의 컴퓨팅 건물·인프라 전체를 100% 물리 정확한 인터랙티브 디지털 트윈으로 OpenUSD 기반에서 구축하게 한다. 네트워크 트래픽·전력 부하·CFD 열 방출을 가상에서 모사해 사전 최적화하고, 로컬 개발은 15~20분 내 구동 가능하다.

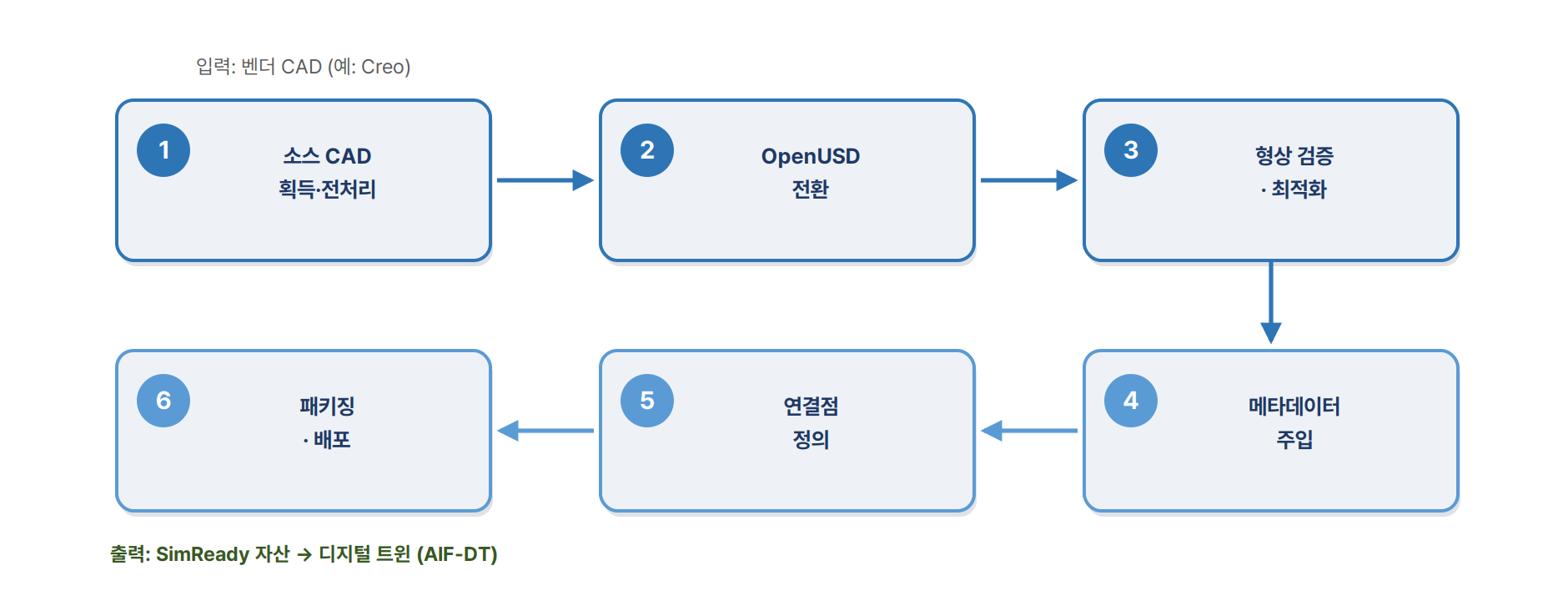
그 토대는 벤더의 단순 CAD를 물리 연산 가능한 ‘SimReady 자산’으로 바꾸는 6단계 파이프라인이다. 가장 혁신적 요소는 대리 모델(Surrogate Model) — 복잡한 물리 방정식을 매번 풀지 않고, 사전 훈련된 AI 가속 모델이 ‘랙 배치를 바꾸면?’ 같은 질의의 영향을 밀리초 단위로 예측한다.
소프트웨어 스택 · 운영 · 생태계
DSX는 CUDA·DGX를 대체하지 않는다. 그 위에 놓인다.
DSX는 CUDA·TensorRT·NGC·DGX·AI Enterprise를 대체하는 레이어가 아니라, 그것들을 조립하고 그 위에서 동작하는 상위 운영·설계 계층이다. 추론 계층은 NIM/NVCF API → Dynamo/TensorRT-LLM → GPU 런타임 패턴을 직접 지정한다. 운영 모범 사례를 한 문장으로 요약하면 — 가동률이 아니라 토큰 생산성을 KPI로 두고, 시뮬레이션으로 먼저 검증한 뒤 GitOps·검증 아티팩트·다계층 텔레메트리·자동 복구로 일관된 Day-2 운영을 만든다.
생태계는 컴퓨팅 OEM(Dell·HPE·Lenovo·Supermicro·ASUS·Foxconn), 클라우드(CoreWeave·Crusoe·Nebius·IREN), 전력·냉각(Vertiv·Siemens·Eaton·Schneider), 디지털트윈·건설(Cadence·Dassault·PTC·Jacobs·Bechtel), DSX OS 채택(Red Hat·Mirantis·Rafay·Vultr 등) 전반으로 확장된다.
유사 ‘AI 팩토리’ 플랫폼(Cisco Secure AI Factory, HPE Private Cloud AI, Red Hat AI Factory, Dell AI Factory)과의 관계는, DSX가 경쟁 제품이라기보다 상위 표준/청사진이고 나머지는 그 위에서 구현되는 제품화된 팩토리에 가깝다는 것이다. 문제 범위가 전력·냉각·그리드·트윈까지 넓어질수록 DSX 가치가 커진다.
무엇이 아직 불확실한가
공개 자료로 확정되지 않은 항목들 — 투자 결정 전 재검증.
| 항목 | 불확실성 |
|---|---|
| “DSX” 풀네임 · “LPS” 의미 | 공식 정의 없음(상표 ™). 외부 풀이는 모두 추정. |
| 50배 처리량 / 35배 비용 | NVIDIA 자체 주장(Blackwell Ultra 대 Hopper). 시험 조건 미공개. |
| 45°C 액체냉각 | MaxLPS 보도자료엔 명시, NCP 기술문서엔 미확인. 일부 OEM은 40°C. |
| 랙 전력 190/370/600kW | 업계 추정. 공식은 NVL72 120~142kW뿐. |
| Vera Rubin = NVL72 | NVL144·NVL576은 Vera Rubin이 아니라 2027 Rubin Ultra(Kyber) 세대 구성. |
| 100GW 미활용 전력망 | 이론적 상한치라는 분석. 실제 검증은 96MW Aurora 파일럿 규모. |
| Max-Q vs MaxLPS | 단순 개명인지 범위 분화인지 미확정. |
세 줄로
첫째, DSX는 칩·서버가 아니라 AI 팩토리 전체를 설계·시뮬레이션·운영하는 ‘산업 표준 청사진’이다 — 평가의 본질은 “성능 좋은 GPU 인프라인가”가 아니라 “칩에서 전력망까지 하나의 생산 시스템으로 만들 수 있는가”이다.
둘째, 빌딩블록 계층에서 DSX는 SuperPOD 위의 데이터센터 레벨에 위치하며, HGX·MGX·DGX·POD와는 다루는 경계와 제공 방식(턴키/브랜드 vs 개방/플레이북)에서 구분된다.
셋째, 전력이 1순위 제약이다 — 800VDC 전환, 랙당 120→600kW 상승, 45°C 액냉, 그리드 연동(Flex)이 ‘메가와트당 토큰’을 좌우한다. 단, 50배·35배 같은 핵심 수치 상당수는 NVIDIA 주장이거나 업계 추정이라는 점을 잊지 말 것.
CLOSING
NVIDIA는 ‘칩을 파는 회사’에서 ‘공장 짓는 법을 파는 회사’로 이동하고 있다. DSX는 그 전환의 이름이다.
대규모 엔터프라이즈·클라우드·주권형 AI 인프라라면 매우 강력한 상위 청사진이고, 중간 규모의 빠른 전개라면 DGX 플랫폼이나 파트너 구현체가 더 실용적이다. 어느 쪽이든, 먼저 디지털 트윈으로 검증하고 토큰 생산성을 KPI로 두는 운영 모델은 공통의 출발점이다.
주요 링크
- NVIDIA DSX 제품 페이지 — https://www.nvidia.com/en-us/data-center/products/dsx/
- NVIDIA DSX 문서 홈 — https://docs.nvidia.com/dsx/home
- 뉴스룸 — DSX, AI 팩토리 플레이북 — https://nvidianews.nvidia.com/news/dsx-infrastructure-ai-factory
- 뉴스룸 — Vera Rubin DSX & Omniverse DSX Blueprint — https://nvidianews.nvidia.com/news/nvidia-releases-vera-rubin-dsx-ai-factory-reference-design-and-omniverse-dsx-digital-twin-blueprint-with-broad-industry-support
- DSX OS — Open, Modular Software (기술 블로그) — https://developer.nvidia.com/blog/nvidia-dsx-os-delivers-open-modular-software-for-operating-ai-factories-at-scale/
- Vera Rubin POD — 7 chips, 5 rack-scale systems (기술 블로그) — https://developer.nvidia.com/blog/nvidia-vera-rubin-pod-seven-chips-five-rack-scale-systems-one-ai-supercomputer/
- Gigawatt AI Factories · OCP · 800VDC (블로그) — https://blogs.nvidia.com/blog/gigawatt-ai-factories-ocp-vera-rubin/
- Omniverse DSX Blueprint 문서 — https://docs.omniverse.nvidia.com/dsx/latest/index.html