AI 개발에 대규모 GPU는 필수적인 요소로 간주된다. 한국 정부는 2025년 초 부족한 GPU를 공공 인프라 형태로 제공할 계획을 발표하였다. 이 시리즈의 핵심 주제이기도 하다. 그런데 국내외적으로 다양한 설계를 기반으로 다양한 Hardware Accelerator(Co-processor)가 출시되고 있고, 성능 평가 결과를 공표하면서 자신들의 새로운 하드웨어를 뽑낸다. 하지만, 현실은 AI 모델 학습은 NVIDIA의 GPU가 거의 독점적으로 사용되고 있다. 국내 S모사는 AMD의 하드웨어를 대규모로 구매해서 사용한다는 기사가 있었지만, 그외 다른 회사들이 AMD의 하드웨어를 AI 학습용으로 사용한다는 이야기는 잘 들리지 않는다. 그런데 정부에서는 AI Chip 활성화를 AI 국내 기술 개발의 하나의 축으로 삼는듯한다. 이번 포스트에서는 NPU가 왜 GPU 보다 특정 연산에서 성능이 더 잘 나오는지 알아 보고 GPU 전성시대에 NPU의 활용법과 확대 방안에 대해서 논의 해보도록 하겠다. 그리고 좋은 성능에도 불구하고 NPU, TPU등이 왜 GPU보다 사용이 덜되고 있는지도 알아 보겠다. 우선 NVIDIA의 GPU의 공고함이 어떻게 발생했는지 먼저 알아 보겠다.
NVIDIA GPU로 공고히 만들어진 기라성
여러 뉴스 또는, 여러 홍보에서 GPU의 성능을 추월했다는 것을 들을 수 있다. 그런데 여전히 NVIDIA의 GPU가 가장 많이 활용되고 있다. 왜 그럴까? NPU, TPU 기업의 성능은 거짓이 없음에 분명하기 때문에 더더욱 의아하다. 왜 그럴까? 크게 2가지 원인이 있다. 첫 번째는 NPU는 AI에 특화되어 있고, 특정 모델이나 특정 연산에 최적화 되어 있다. 다시 발해서 범용성 측면에서 부족함이 있다. 반대급부로, 이로 인해서 비용 및 특정 목적에 성능이 최대화 될 수 있다. 두 번째는 소프트웨어 생태계(Eco)/툴체인(Toolchain) 측면이다. 이번 단란에서는 이 두 번째에 대해서 이야기 해보겠다.
첨부한 그림은 NVIDIA의 CUDA Software Stack에 허깅페이스가 가장 위에 있는 생태계를 그린 그림이다. Sora로 3D로 만들어서 일부 글자가 깨져 옆에 원본 그림도 함께 배치 하였다. 원 그림에는 관련된 내용 출처도 함께 포함되어 있다.

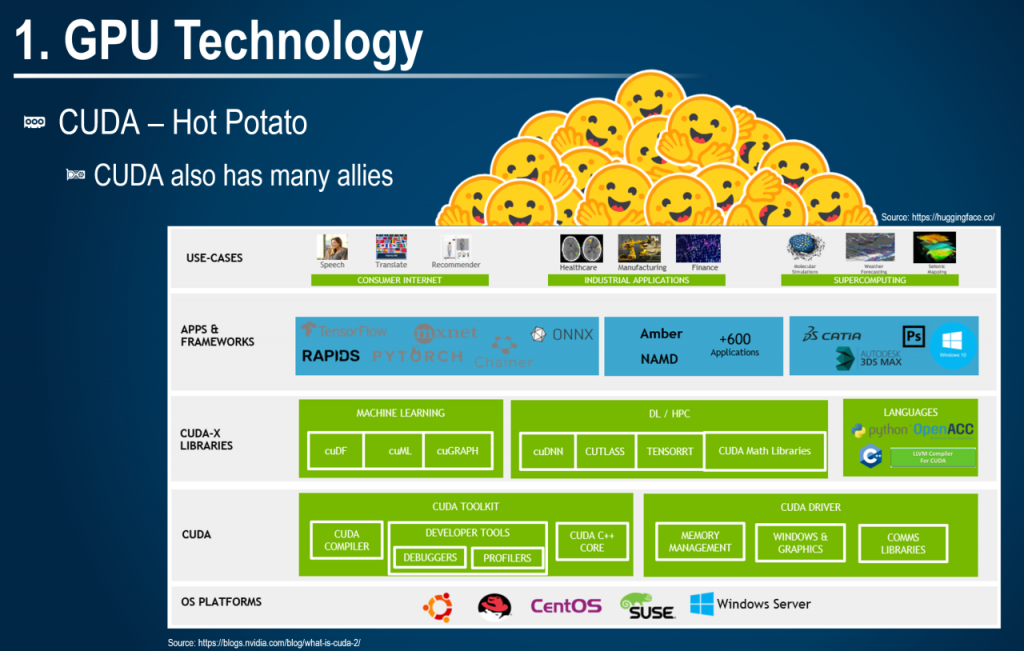
우선 NVIDIA가 자체적으로 구축한 CUDA, CUDA-X를 살펴 보자. CUDA는 GPU에 데이터를 보내고 연산용 코드를 전달하기 위한 가장 기본적인(Primitive) 라이브러리를 기반으로 기계학습, 딥러닝, HPC를 위한 추가적인 라이브러리들이 포진되어 있다. 이 자체가 이미 너무 방대하고, 이 방대함은 1~2년만에 구축된 것이 아니다. OpenCV를 표준으로 가져가지 않고 CUDA를 자체적으로 개발해서 진행한 십수년의 노하우가 들어가 있다. 이것이 첫 번째 기술장벽(Entry Barrier) 이다. 잘 기억하고 두 번째로 넘어 가 보자.
두 번째는 NVIDIA가 자체적으로 구축하지 않은 CUDA를 기반으로 한 각종 ML Framework(F/W)와 MF F/W에서 사용하는 각종 수학, ML/DL 라이브러리이다. 텐서플로우, 파이토치, ONNX 등이 여기에 해당된다. 그외에도 각종 과학기술용 상용/오픈 라이브러리들이 있는데, 첫번째 기술장벽위에 엎혀진 두 번째 기술장벽이다. 많은 사람들이 이 기술장벽에 대해서 잘 인지하지 못하고 있고 이어질 세번째 기술 장벽이 가능한 가교 역할을 한다.
마지막의 기술장벽이 매우 중요함!!!! 첫 번째, 두 번째 기술장벽은 눈에 잘 보이거나 인지하기 쉽다. 왜냐하면 직접적인 산출물이 명시적으로 존재 하기 때문디다. 마지막 기술장벽은 첫 번째, 두 번째 기술장벽을 활용한 특히 두 번째 기술장벽을 활용해서 쌓아 올려진 노하우이다. 두 번째 장벽을 기반으로 각종 ML Architecture(각종 CNN 아키텍쳐, Transformer)가 만들어 지고 ML을 서비스로 제공할 수 있는 서빙 프레임워크들이 존재한다. vLLM, SGLang, TensorRT 등이 이에 해당한다. 최근에는 이런 각 개인의, 연구 단체의 노하우가 컨테이너에 구체화 되어 허깅페이스에서 제공된다. 최신 Open Source LLM을 vLLM으로 서빙하는데 하드웨어만 있다면 수십분 안에 서비스를 제공할 수 있는데 기술장벽인 동시에 편리성을 제공한다. 이것이 세 번째 기술장벽입니다.
첫 번째, 두 번째 그리고 세번째 기술장벽은 특정 몇명, 특정 몇개의 기업이 단기간에 만든 생태계가 아니다. 수십년에 Try and Error를 통해서 공고히 쌓여진 생태계이다. 다시 처음으로 돌아가보자. NPU/TPU 개발 기업의 기술력은 매우 뛰어남을 의심할 여지가 없다. 많은 노력을 기울여 첫 번째 기술장벽을 일시적으로 극복할 수 있다. 그런데 지금 만들어진 생태계를 멈춰있지 않다. 그래서 첫 번째 기술장벽이 다시 공공해지고 이를 깨기 위한 지협적인 노력에 힘이 더더욱 들어 간다. 두 번째, 세 번째의 기술장벽은 깨는 것은 아마도 엄두도 못낼 것이다.
이렇게 공고한 기술장벽이 있는데 NPU를 왜 소개하냐고 반문할 수 있을 것이다. 하지만 저 장벽을 잘 이용하면 NPU/TPU도 이 생태계에 들어 올 수 있을 것이라 생각하다. 이 부분은 마지막에 알아 보도록 하겠다. 이제 NPU 기술에 대해서 알아 보자.
NPU – Neural Processing Unit
NPU는 Neural Network 연산에 최적화 되어 있는 하드웨어 이다. GPU, CPU가 가지고 있는 병렬처리 구조를 먼저 이해해야 NPU의 Neural Network에 특화되어 있는 연산을 이해 할 수 있다. 다른 포스팅의 GPU, CPU의 병렬처리 기법을 이해한 후에 아래 내용을 읽으면 조금 더 대비되는 점을 알 수 있다. (관련 링크 추가 예정). 개념적으로는 GPU, CPU, NPU, TPU 모두 동일한 연산에 대해서 여러개의 연산장치가 동일한 형태의 다른 값을 가진 많은 데이터를 동시에 처리 한다고 생각하면 된다. NPU/TPU는 기본적인 병렬처리에 추가적인 기법을 더한 것이다. 이때 사용되는 주요 기술이 시스톨릭과 효율적인 메모리 관리 입니다. 효율적인 메모리 관리는 AI 연산에 최적화된 메모리 관리를 의미 합니다. 범용성을 담보하지는 못합니다. 데이터 Quantazation도 초기에는 많이 사용되었지만, 현재는 ML 자체에서 소프트웨어적으로 만이 사용되어서 현재는 NPU 효용성은 없어 보인다. 그리고 중심이 되는 기술을 활용하고 각 AI 칩마다 고유의 특징이 반영되어 있다. 하나씩 알아 보자.
시스톨릭(Systolic)
시스톨릭 아키텍처 또는 시스톨릭 연산이라고 불리는 시스톨릭은 행렬 연산에 최적화 되어 있는 하드웨어 또는 소프트웨어 연산 기법이다. 병렬 처리에서 동시 처리 보다 중요한 부분이 데이터가 계산이 필요한 곳에 가장 알맞은 시기에 도착해 있는 것이다. 이를 위해서 Pre-Patch를 할 수도 있고, Pipiline을 잘 설계할 수 도 있지만 Host에서 Accelerator로 데이터 복사가 빈번할 경우 성능 저하가 발생할 수 있다. 시스톨릭 아키텍처는 데이터 연산시 데이터 복사가 최소화 되도록 하는 방법이다. 이는 PE(Processing Element)가 독립된 NPU 계열이 처리가 유리하기 때문에 GPU보다 NPU 계열에서 많이 사용 되는 방법이고, 이를 통해서 Memory Locality를 향상할 수 있다. 구글의 TPU, Furiosa, GraphCore IPU에서 모두 사용하는 방법니다.
아래 그림은 Matrix Multiply를 그림으로 나타낸 그림 이다. 그림을 통해서 시스톨릭에 대해서 알아 보자. A Matrix와 B Matrix를 곱해서 C Marix에 저장한다고 할 때, A Matrix A00이 연산에 사용 되는 C Matrix 위치에 빨간색 동그라미를 표시 하였다. 같은 방법으로 B Matrix의 B00을 파란색 동그라미로 표시 하였다.
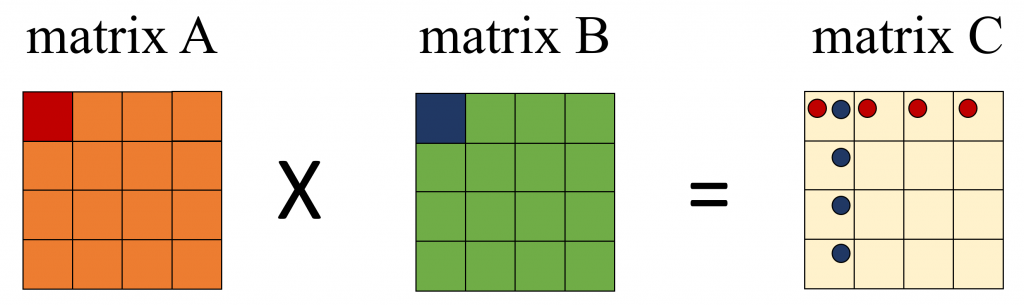
C00은 A00, A01, A02, A03각각과 B00, B10, B20, B30각각을 곱한 값을 더한 결과다. C01은 A00, A01, A02, A03 각각과 B10, B11, B12, B13각각을 곱한 값을 더한 결과다. 이런 식으로 생각해 보면 A00는 C00, C01, C02, C03 연산에 사용된다. B00는 C00, C10, C20, C30 를 계산하는 연산에 사용됩니다. A00, B00등을 계산시 마다 Offloading을 하면 아주 많은 Cost가 발생할 것이다. 시스톨릭은 혈관에 혈액이 흐르듯이 이 A00, B00를 PE들이 연산할 수 있도록 첫번째 연산시에만 Offloading을 하고 PE간 데이터를 이동하면서 사용하는 방법이다. 당연히 PE에 Local 메모리가 존재 해야만 한다. 많은 NPU들이 Local Cache, Local Memoery를 가지고 있기 때문에 Offloading의 Overhead를 극복할 수 있는 것이다. 아래 그림이 보시면 이해가 쉬울 것이다. C Matrix의 각 엘리먼트의 연산을 1개의 PE가 담당한다고 가정한다.
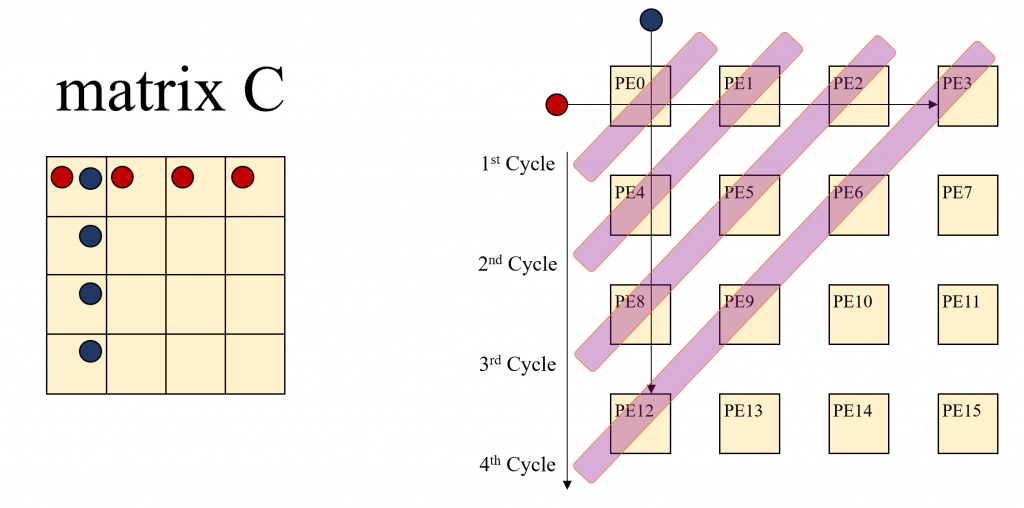
시스톨릭 아키텍처에서는 앞서 설명한 것처럼 A00, B00가 가장 먼저 offloading 된 후에 곱해진 후에 C00에 저장된다. A00, B00는 다음 연산을 위해 각각 C01, C10으로 이동한다. 그리고 다음 연산을 위해서 데이터가 추가로 offloading 되고, C00 의 전체 연산의 다음 계산을 위해서 A01, B10이 Offloading되고 C01에서 A00와 계산될 B01이 C10에서 B00와 계산될 A10 이 Offloading 된다. 이런 연산을 수행하면 연산의 순서가 왼쪽 상단에서 부터 오른쪽 하단으로 연산이 확산되는 것을 알 수 있다. 새롭게 Offloading된 데이터는 A Matrix 값은 Row Index를 유지하면서 오른쪽으로 B Matrix으 값은 Column Index를 유지 하면서 아랫쪽으로 이동하면서 연산에 사용된다.
바로 위 오른쪽 그림을 Cycle을 X축으로 다시 그린 그림을 GraphCore의 IPC Whitepaper에서도 소개 하고 있다.

그림에서 보는 것처럼 행렬 연산에 최적화 되어 있는 하드웨어 구조이다. 하지만 NVIDIA GPU는 처음부터 이 구조를 가지고 있지 않았다. NVIDIA GPU는 병렬처리가 필요한 범용 대규모 연산에 최적화 되어 있기 때문이다.
메모리 계층 구조(Memory Hierarchy)
시스톨릭이 제대로 동작하기 위해서 필요한 선행 조건이 있다. 시스톨릭은 PE가 행렬의 한 요소 처럼 동작하고 계산을 위한 데이터가 흘러 들어 오는 구조이다. 이를 위해서는 PE에 데이터가 적절하게 공급이 되어야 한다. 적절하게는 공급이 된다는 것은 계산에 필요한 시점에 데이터가 준비 되어 있어야 한다는 것이다. NPU, TPU 등은 폰 노이만 아키텍쳐에서 보조연산장치 이기 때문에 메인 메모리에서 데이터가 NPU로 공급되는데 상당히 많은 시간이 필요합니다. 단 한번의 메모리 전달(또는 복사)는 눈깜짝할 시간 보다 짧지만 데이터가 수백만, 수백억번 복사가 반복이 될 때 발생하는 성능 저하는 눈깜짝할 시간이 아닌 엄청난 시간을 메모리 전달을 위해서 사용하게 된다. 그래서 이런 반복된 메모리 전달에서 오는 성능 저하를 최소화 하기 위해서 여러가지 기법들이 예전 부터 사용되고 있었다. 특히 계산을 위한 데이터를 사전에 복사하는 Pipelining, Offloading 최적화 등은 잘 알려진 기법이다. 이런 기본적인 기법은 거의 빠짐 없이 적용되어 있지만, LLM 시대, DL 시대에는 여전히 성능 저하가 꽤 존재 한다.
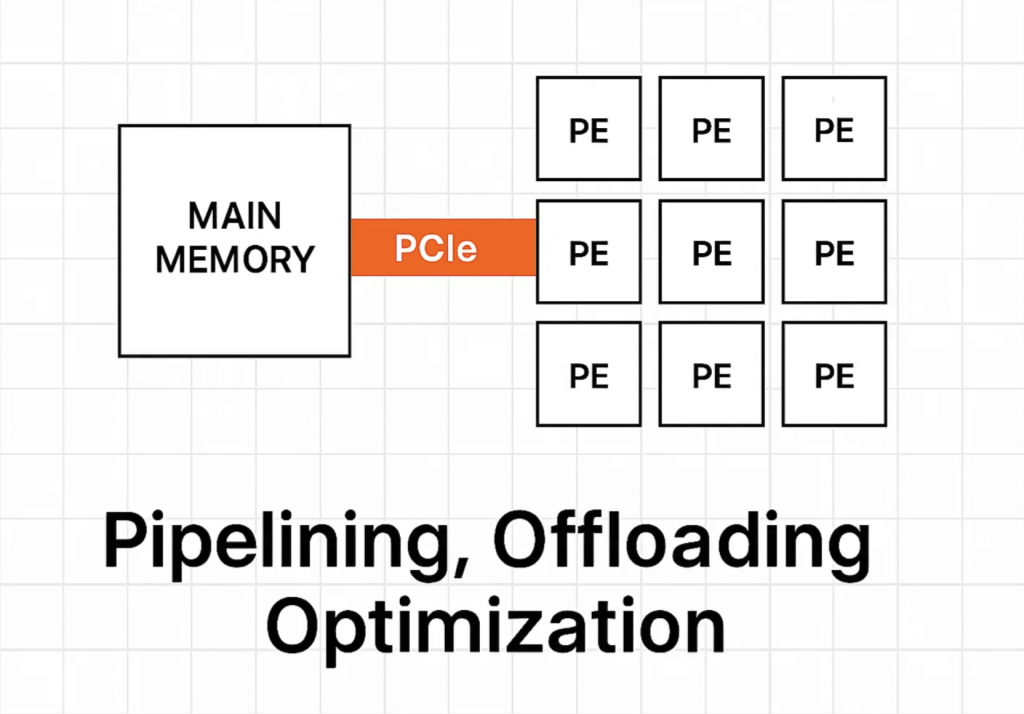
바로 이 성능 저하(Overhead)를 제거 하기 위해서 NPU 설계시 다층 구조의 메모리를 가진다. 메모리의 다층 구조는 일반적으로 사용되는 컴퓨터 구조에서 찾아 볼 수 있다. 흔히 말하는 L1, L2, L3 Cache가 메인 메모리에서 CPU로 데이터가 전달되는 시간을 단축하기 위해 Cache를 체계적으로 가지고 있고 이를 활용한다. 보조연산장치도 유사한 구조를 가지고 있다. 하지만 PE가 많은 구조에서는 L1 레벨의 Cache를 모두 가지는 것은 비용적인 문제가 있기 때문에 초기에는 잘 적용되지 않았다. 그 대신 L3, L2 레벨의 Cache의 활용이 활발 했습니다. 초기 보조연산장치에서는 큰 문제가 없었으나 Neural Architecture가 커지고 텐서연산이 기하급수적으로 높아 지면서 L1을 도입하고 앞에서 설명한 시스톨릭 아키텍쳐의 장점을 극대화 하게 된다. GraphCore의 IPU 백서를 보면 특징이 가장 도드라 진다.

IPU Core(PE)마다 바로 근접한 위치에 메모리가 위치해 있다. 시스톨릭 아크텍처에서 전달된 데이터를 저장하는 빠른 메모리로 사용이 된다. 국내사인 리벨리온사의 하드웨어 구조를 보면 조금 추상적이지만 이 메모리 구조를 확인할 수 있다. 아래 그림은 리벨리온 홈페이지에서 다운로드 받은 백서에서 캡처 하였다.
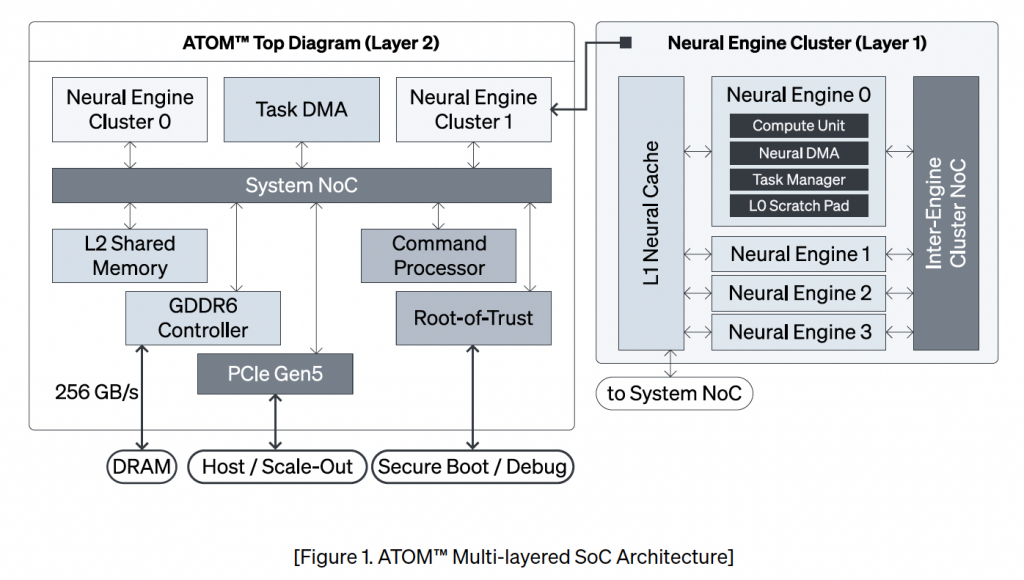
리벨리온 NPU 개념도(출처: ATOM™ Architecture 백서)
왼쪽 그림을 보면 ATOM 보조연상장치(보조라고 하니 부정적인 억양이 있어 Co-processor로 이후 지칭하도록 하겠음)의 구조이다. Co-processor와 Host가 연결되는 구조이고 Nerual 연산을 배치하는 등의 역할을 하는 유닛들과 L2 Cache가 있다. Co-Processor내에 여러개의 Nerual Engine Cluster가 몇개 존재 하고, Nuerual Engine Cluster내부에는 L1 Cache와 여러개의 Neural Engine이 존재 한다.
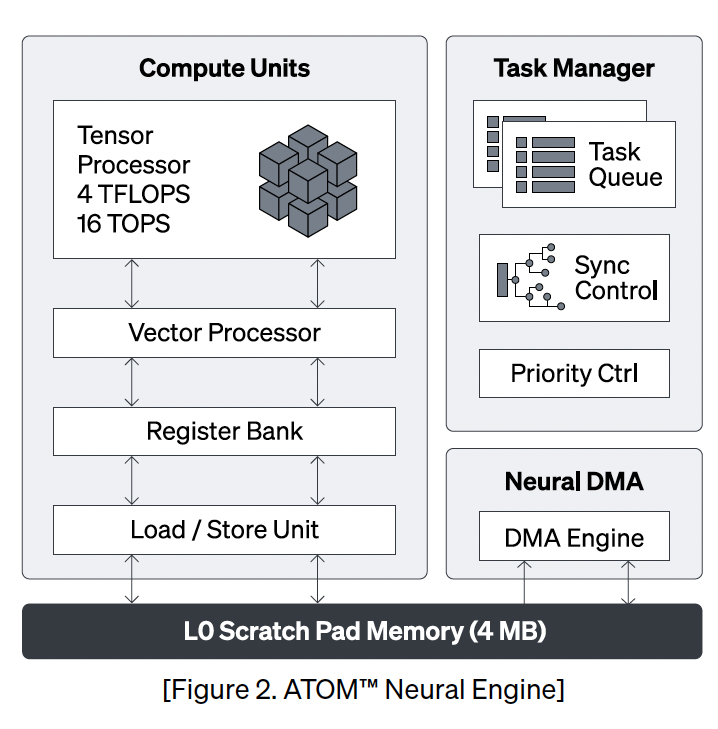
오른쪽 그림이 여러개의 Neural Engine 내부이다. 엔진 자체에 L0 Cache가 존재 하고 Tensor 연산 유닛이 존재 한다. L0 Cache는 시스톨릭 아키텍처에 도움을 준다. 꼭 텐서 연산뿐 아니라도 Co-Proceesor의 L2 Memory의 값비싼 접근을 L1, L0 Cache를 통해서 성능 부하를 감소 시킨다.
메모리 계층 구조에도 단점은 있다. Cache miss가 빈번히 일어나는 알고리즘의 경우 Cache가 없는 경우보다 더 높은 성능 부하를 가질 수 있다. 그래서 Cache miss가 최소화가 되도록 코드가 최적화 되어 있어야 한다. 그리고 외부 메모리를 가져 올때 큰 성능 부하가 있다. 이때 이를 줄여 줄 수 있는 구조가 DMA(Direct Memory Access)이다. DMA는 원격의 메모리를 메모리를 관리하는 Processor 또는 메모리 관리 모듈을 거치지 않고 마치 하나의 가상의 메모리 처럼 접근할 수 있다. 이를 위해서 NoC 등이 하드웨어적으로 직접 연결되어 있다.
그외 성능 최적화 방법
많은 NPU가 추가적으로 가지고 있는 구성요소가 DL, LLM에 특화된 연산을 하드웨어적으로 구현한 경우도 있지만, 통상 행렬곱을 하드웨어로 직접 구현한 경우가 가장 일방적이다. 하지만 NVIDIA의 Volta Architecture 부터 Tensor core의 지원으로 NPU의 특화된 하드웨어 연산이라고 할 수는 없다. 그리고 DL, LLM에 특화된 연산의 경우 특정 Neural Architecture에만 특화될 수 있기 때문에 장점이라고만 하기 어렵다. 대표적인 경우가 국내의 Furiosa의 NPU이다. 1세대는 CNN 연산을 중심으로 2세대는 LLM을 중심으로 연산 최적화를 하드웨어적으로 진행하였다.
전부는 아니지만 일부 NPU는 흥미로운 특성을 가지고 있습니다. GPU를 비롯한 NPU들은 동일한 형태의 대규모 데이터를 동일한 연산으로 처리하는 SIMD(Single Instruction Multiple Data)을 극대화하는 구조입니다. SIMD는 대규모 데이터를 연산만 반복할 때 최선의 결과가 나오는데 만약 분기문이 포함되어 있거나 다양한 경우를 고려해야 하는 경우라면 오히려 성능이 저하될 수 있습니다. 이런 단점을 극복하기 위해서 GraphCore IPU, 리벨리온의 NPU는 MIMD(Multiple Instructions Multiple Data) 코어를 추가적으로 가지고 있거나 코어 자체가 SIMD, MIMD를 모두 지원하는 형태를 가지고 있습니다. 다양한 형태의 계산 방식과 로직을 처리하더라도 최대의 성능을 밝휘하기 위함이죠.
NPU를 위한 생태계 동화, 창조 전략
NPU 제조사들의 주장과 NPU의 연산 능력이나 DL, LLM에 최적화된 설계를 보면 GPU가 바로 NPU로 대체 될 것처럼 보이지만 이 글의 처음에서 봤던 것처럼 공고히 만들어져 있는 GPU의 생태계에 동화 되기 어렵고 GPU와 유사한 생태계를 만들기 어렵다. 가장 근본적인 이유는 각 NPU를 운용하기 위한 드라이버, 소프트웨어, 선형 라이브러리 등은 각 하드웨어에 적합하게 만들어져야 하기 때문이다. 각 Co-Processor의 동작 흐름이나 구성이 다르기 때문에 당연한 일이다.
하드웨어의 특성을 가장 잘 활용하기 위해 직접적이고 가장 효과적인 방법은 각 Co-Processor의 드라이버 및 SDK를 직접 만들고 활용할 수 있도록 하는 것이다. SDK는 자체적으로 만들때 2가지 접근을 할 수 있다. 파이썬에서 사용이 가능한 패키지를 제공하는 방법과 파이썬의 확장 형식에 맞게 인터페이스를 구현하여 확장하는 방법이다. 두가지 방법 모두 장단이 있다. 별도의 라이브러리로 제공될 경우 C++ 또는 Rust를 사용하여 성능에 최적화된 라이브러리를 제공할 수 있는 장점이 있는 반면, 프로그래밍 모델을 자체적으로 만들어야 하는 부담이 있다. 또한 별도로 만들어진 프로그래밍 모델의 경우 새로운 사용자의 유입에 상당한 심리적인 장애가 될 수 있다는 점이다. 파이썬 또는 텐서플로우의 확장 형식을 사용할 경우 이전 사용자들이 하드웨어를 변경하는데서 오는 심리적인 장벽은 제거 할 수 있지만 해당 ML Framework에서 지원하는 프로그래밍 모델을 그대로 따라야 하기 때문에 경우에 따라서 최적의 성능을 확보할 수 없는 단점이 있다. 이 두가지를 표로 정리해 보면 다음과 같다.
| 접근 방식 | 장점 | 단점 |
| 별도 라이브러리 (C++/Rust 패키지) | C++ 또는 Rust를 사용하여 성능에 최적화된 라이브러리 제공 가능 하드웨어의 특성을 가장 잘 활용할 수 있도록 직접적인 제어 및 최적화 가능 | 프로그래밍 모델을 자체적으로 만들어야 하는 부담 새로운 사용자의 유입에 상당한 심리적인 장애 (새로운 학습 곡선) |
| 파이썬/텐서플로우 확장 형식 | 기존 사용자들의 하드웨어 변경에 대한 심리적인 장벽 제거 (친숙한 프로그래밍 모델 유지) 기존 ML 프레임워크의 풍부한 기능 및 생태계 활용 가능 | 해당 ML 프레임워크에서 지원하는 프로그래밍 모델을 그대로 따라야 함 경우에 따라 하드웨어의 최적 성능을 확보하기 어려울 수 있음 |
잠시 파이썬의 하드웨어 확장 형식에 대해서 살펴 보도록 하자, 위 이야기에 대한 이해뿐 아니라 NPU가 이전 생태계에 잘 동화되기 위한 전력 역시 비슷한 방식이기 때문이다. 파이썬은 GPU, NPU등의 하드웨어 리소르를 ProcessGroup으로 묶어서 allreduce, allgather등을 추상화 하여 사용한다. 앞서 시스톨릭을 설명할 때 나왔던 Processing Element(PE)를 기본 개념으로 넣고 다양한 MPI 기반 연산을 추상화 한 것입니다. 파이썬의 공식 레파지토리에 올라온 포트(Port, Plugin)은 NCCL, MPI, Gloo(CPU), UCX, oneAPI(Intel 분산처리 및 연산 통합 API)이다. 관계도를 그림으로 표현하면 아래 그림과 같다.
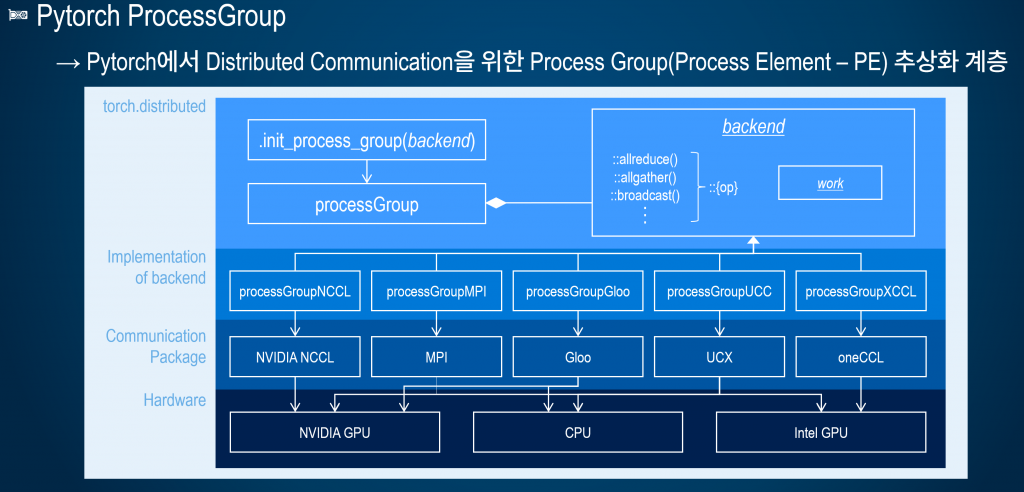
파이썬, 텐서플로우 확장 형식을 따를 경우 원칙적으로는 신규 하드웨어에서 학습 및 추론에 모두 사용될 수 있다. 악마는 디테일에 있다고 한다. 실제로 추상화된 API를 구현하고 프로그래밍 모델을 따르더라도 정상동작하지 않는 경우도 많을 것이며, 특히나 파이썬의 프로그래밍 모델로 동작 했을 경우 기대하는 성능에 한 참 못 미치일 수 있다. 이 부분은 구현 후 최적화에 엄청난 공을 들여야 하는 부분이다. 이런 예상되는 어려움에도 불구하고 파이썬, 텐서플로우의 확장을 이용해야 하는 이유는 앞서 이야기한 생태계에 동화되기 위함이다. 앞에서 이야기한 GPU를 기반으로 한 생태계의 중간 지점에 파이썬과 텐서플로우가 있다. 이 두가지 ML Framework를 기반으로 동작하는 생태계는 두 ML Framework의 프로그래밍 모델을 잘 수용할 경우 쉽게 활용할 수 있다. 물론, 별도의 라이브러리를 활용한 생태계의 경우 각기 1대1 대응을 해야 하는 것에는 변함이 없다.
LLM 생태계로의 NPU 동화 전략
LLM은 NLP의 특수한 한 분야이다. 그리고 NLP를 DL로 풀어낸 분야이기 때문에 DL의 한 분야이다. 하지만, 현재 AI, 더 나아가 전세계 Tech의 가장 큰 분야이기 때문에 DL에서의 전략에 확장으로 전개 할 수 도 있고, 별도의 LLM 전략을 전개 할 수 도 있다. LLM 전략을 별도로 전개 한다고 해서 LLM 중 특정 모델이나 분야만을 대상으로 한다는 것은 아니다. LLM 관점에서도 두 가지 전략을 생각할 수 있다. 앞서 이야기 했던 두 가지 전략중 두 번째 전략을 확장한 전략이다. 다음과 같은 두가지 전략을 생각할 수 있다. 그리고 이 두 전략의 전제는 혼자서가 아니라 오픈 소스 진영의 표준화된 규약을 따라서 함께 성장할 수 있는 환경을 구축하는 것이다.
- vLLM의 플랫폼(하드웨어) PlugIn을 활용한 LLM 생태계 동화
- OpenSource 진형의 하드웨어 확산 전략을 활용한 LLM 생태계 동화
1. vLLM의 플랫폼(하드웨어) PlugIn을 활용한 LLM 생태계 동화
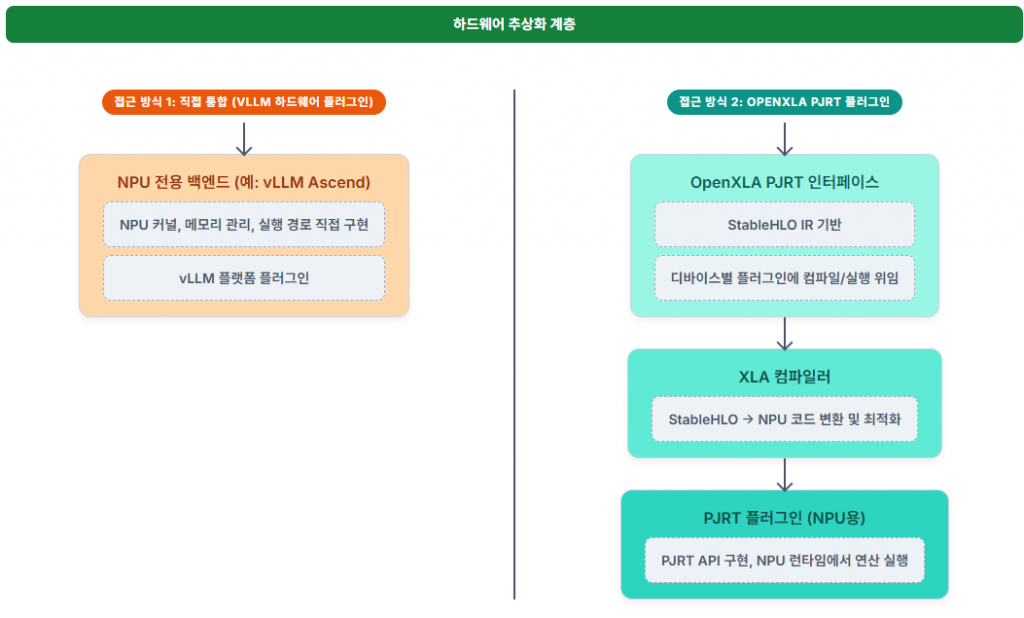
얼핏 보면 두가지가 같은 전략인 것 같지만, 살짝 다르다. 우선 vLLM을 활용하는 전략은 현재 LLM Serving에 De-facto가 되어가고 있는 vLLM을 충실히 지원하는 방법이다. 이는 파이썬, 텐서플로우의 프로그래밍 모델을 지원하는 전력과 완전히 동일하지만 대상이 ML Framework가 아닌 LLM Serving Framework이라는 것이다. 파이썬과 유사하게 vLLM은 플랫폼(하드웨어) 확장을 지원한다. 그림으로 개략적으로 표시 하면 아래와 같다.
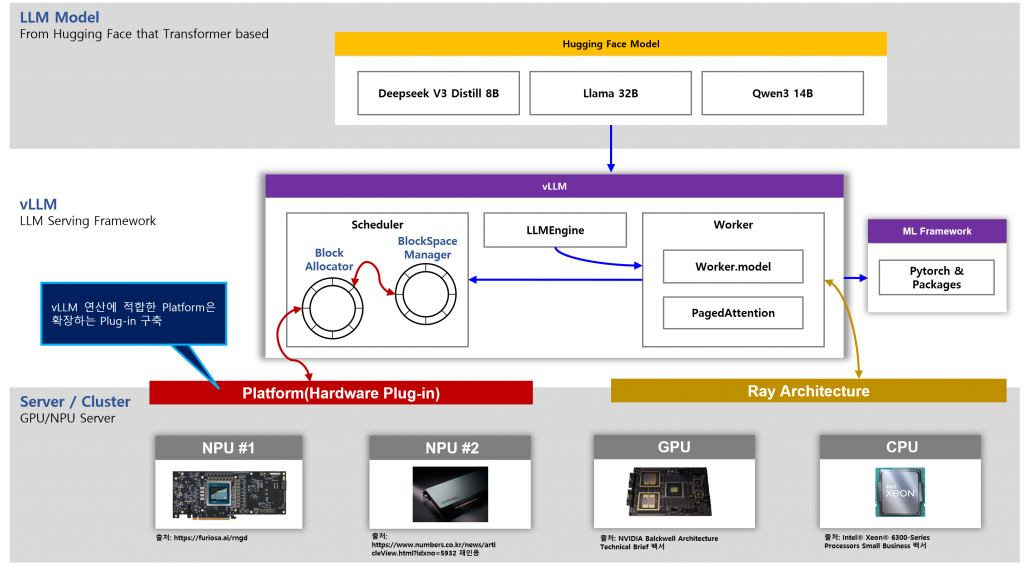
이 전략을 펼치고 있는 가장 대표적인 NPU 제조사가 화웨이이다. 화웨이는 자사의 Ascend NPU를 vLLM의 Platform으로 지원하려고 하고 있다. 철저하게 vLLM의 Platform Plugin 정책을 그대로 따르고 있다.

관련된 내용은 다음 블로그에서 자세히 확인해 볼 수 있다 – ‘Introducing vLLM Hardware Plugin, Best Practice from Ascend NPU’ (https://blog.vllm.ai/2025/05/12/hardware-plugin.html). vLLM의 PlugIn으로 NPU를 사용할 수 있게 하면 여러가지 장점이 있다. NPU는 vLLM의 PlugIn을 문제 없이 지원하고, 자사의 하드웨어 버전에 따른 유지보수만 신경 쓰면 된다. vLLM은 vLLM 기능이 지속적으로 업데이트가 된다. 중요한 부분이 바로 이 부분이다. vLLM과 NPU는 각기 업그레이드를 지속하지만 상호 연관이 되는 Interface만을 지킨다면 정상 동작을 담보할 수 있는 것이다. 이는 객체지향 설계 원칙 SOLID 중 ISP(인터페이스 분리 원칙)이다. 포스팅에서 반복되었던 단어를 사용하면 생태계에서 나 자신은 본인의 역량을 최대화 하여 가장 적합한 영역에서만 노력하고, 다른 부분들은 다른 플레이어들이 노력을 해서 전체 생태계가 발전하게 되는 것이다.
2. OpenSource 진형의 하드웨어 확산 전략을 활용한 LLM 생태계 동화
vLLM이 사실상 표준으로 자리 잡았으나, Transformer based LLM Serving Framework이라는 한계를 가지고 있다. 즉, 학습에 사용될 수 없고 다른 DL 모델을 활용할 때에는 적용할 수 없다는 이야기 이다. 그렇게 때문에 NPU 활용을 LLM Serving 이상으로 활용하기 위해서는 다른 확산 전략이 필요하다.
vLLM은 오픈소스이다. 다만, 적용 분야가 한정적이라는 작은 단점이 있을 뿐이다. 미국, 유럽의 소프트웨어 개발자들은 늘 개방된 표준, 특정 벤터의 락인에 대해서 굉장히 부정적이다. NVIDIA GPU에 대해서도 비슷할 것이다. 비단 대한민국에서만 NPU를 만들고 있지 않을 것이고, 많은 하드웨어 업체들이 NPU, LPU, IPU 등등 다양한 이름으로 NPU를 만들어서 판매 하고 있다. 이 수 많은 하드웨어를 가지고 모델을 추론에 이용하고자 할 때 호환성 이외에도 인터프리터로 된 모델의 성능을 향상하기 위한 노력도 함께 이루어지고 있다. 갑자기 왜 성능 이야기를 하는지 의아할지도 모르겠다. 하지만, 조금만 이야기를 들어 보도록 하자. 인터프린터로 동작하는 파이썬으로 만들어진 모델을 빠르게 동작하기 위해서 XLA(Accelerated Linear Algebra)를 표준화 하고 사용하고 있다. 성능에 최적화 되도록 코드를 변경한다. ML Framework에서 XLA로 바로 변경하는 것은 가능하나 복잡하고 어렵기 때문에 이를 한 번더 추상화한 StableHLO가 존재 한다. ML Framework에서 XLA를 캡슐화 한 표준 연산의 모음이다. 그리고 XLA를 하드웨어로부터 종속성을 제거 하기 위한 메카니즘이 PJRT(Protable JIT)이다. XLA의 최적화된 연산을 하드웨어에서 동작하기 위한 통일되고 추상화된 디바이스 API를 제공한다. 이제 연결고리가 보일 것이다!!!! PJRT를 각 NPU에 맞게 구현하면 XLA를 사용하는 모델 추론/서비스에서 사용할 수 있다는 것이다.
OpenXLA, StableHLO, PRJT를 연결해서 사용하면 최적화된 모델 구동을 하드웨어에 독립적으로 동작하는 소프트웨어를 구축할 수 있습니다. 바꾸어서 말하면 OpenXLA, StableHLO, PRJT를 연동해서 구축된 소프트웨어는 다양한 NPU에서 지원할 수 있다는 것입니다. 그리고 OpenXLA는 ML Framework에서 모두 채택 했기 때문에 모든 ML Framework에서 사용할 수 있습니다. vLLM Platform PlugIn 방식과 마찬가지로 생태계가 확장되더라도 이에 따라서 변경되어야 할 내용이 적은 장점이 있습니다. 다만, XLA를 사용할 때 의도와는 반대로 성능이 급격히 떨어지는 경우도 있어서 XLA를 위한 최적화 단계가 반드시 필요하다. 1, 2 번 전략을 비교 하면 아래 그림과 같다.
마치며
AI 하드웨어 시장에서 NPU가 성공적으로 안착하기 위한 핵심은 단순히 하드웨어 성능의 우위를 넘어, 광범위하게 구축된 소프트웨어 생태계와의 조화로운 통합에 달려 있다. 원문이 인용한 “빨리 가려면 혼자 가고, 멀리 가려면 함께 가라”는 격언처럼 , NPU 벤더들은 독자적인 기술 개발에만 몰두하기보다는, 수십 년간의 노력으로 공고히 쌓아 올려진 기존의 강력한 오픈소스 소프트웨어 생태계에 적극적으로 동화하고 기여하는 전략을 채택해야 한다. 이는 PyTorch, TensorFlow와 같은 주류 ML 프레임워크의 확장 형식 지원, VLLM과 같은 LLM 서빙 프레임워크의 플러그인 참여, 그리고 OpenXLA/PJRT와 같은 오픈 표준 이니셔티브에 대한 적극적인 기여를 통해 이루어질 수 있다. 이러한 노력은 NPU가 시장에 성공적으로 진입하고 지속 가능한 성장을 이루는 데 필수적인 요소이다.
이러한 협력적 접근 방식은 단순히 기술적 호환성을 확보하는 것을 넘어선다. 이는 광범위한 개발자 커뮤니티의 지지와 참여를 이끌어내고, 장기적인 산업 표준을 형성하며, 특정 벤더에 대한 종속성(lock-in)을 줄이는 데 기여한다. NPU가 기존 GPU 생태계에 편입되는 것은 그 자체의 정체성을 잃는 것이 아니라, 오히려 AI 하드웨어 생태계를 더욱 다양하고 효율적인 방향으로 확장하며 함께 성장하는 상생의 길이다. 궁극적으로, 이러한 전략적 협력과 오픈소스 생태계에 대한 지속적인 기여는 NPU가 AI 하드웨어 시장에서 지속 가능한 경쟁 우위를 확보하고, 나아가 인류의 삶을 변화시킬 AI 기술의 발전에 기여하는 핵심 동력이 될 것이다. 정부의 AI 칩 활성화 정책과 맞물려 , NPU는 미래 AI 인프라의 중요한 축으로서 그 잠재력을 최대한 발휘할 수 있을 것으로 기대된다.