이번 포스팅에서는 GPU가 어떻게 AI 시대의 핵심이 되었는지를 알아보겠다. 우선 GPU의 탄생 배경에 대해서 이야기를 좀 하려고 한다. GPU라는 기술은 결국 연산을 수행하는 장치이고, 그 연산 능력은 반도체 기술의 진보에 직접적으로 영향을 받기 때문에, GPU의 현재를 이해하기 위해서는 반도체 기술의 발전 과정을 짚어보는 것이 자연스럽다고 생각한다.
무어의 법칙
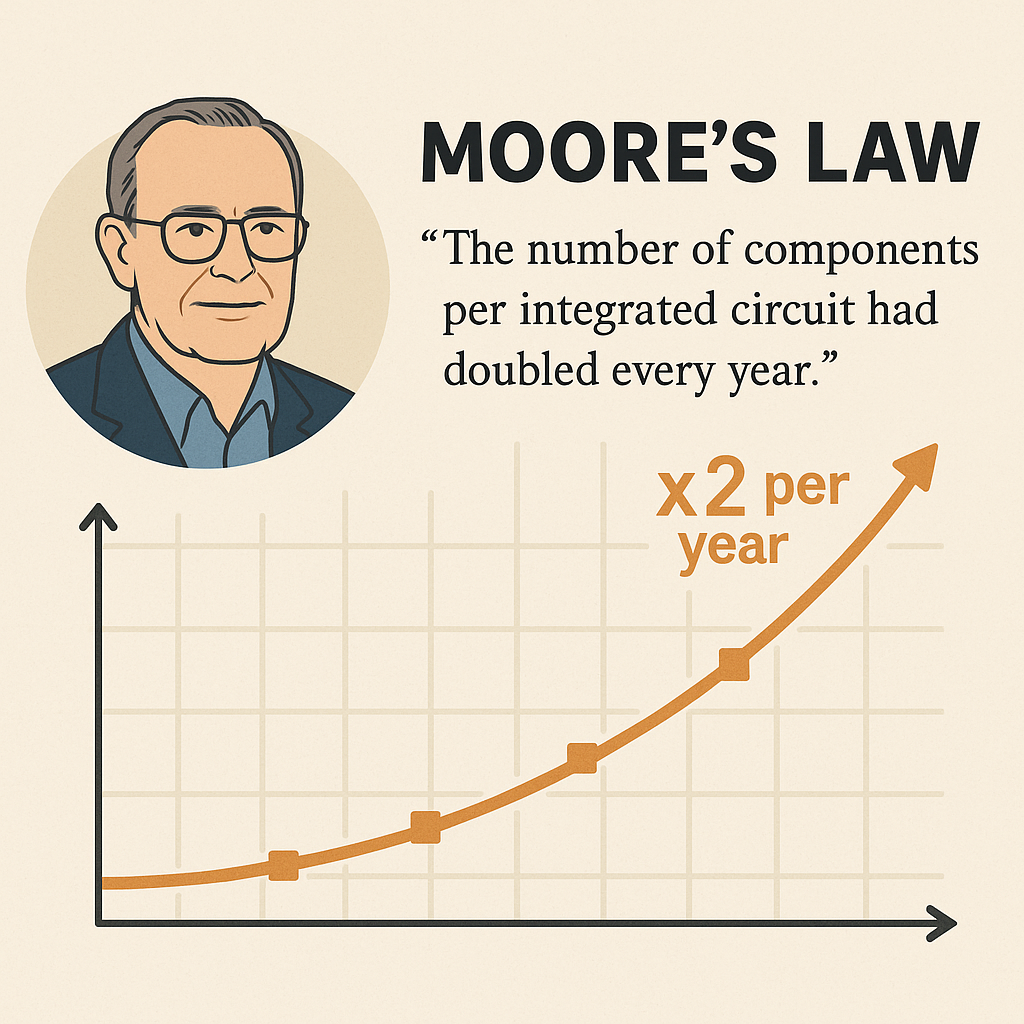
반도체에 대해서 이야기하다 보면 가장 많이 나오는 이야기가 바로 무어의 법칙(Moore’s Law)이다. 무어의 법칙은 인텔의 공동창업자인 고든 무어가 했던 말로부터 유래한 개념이다. 이 개념은 시간이 지남에 따라 기술계와 산업계 전반에 큰 영향을 미쳤고, 수많은 기사나 기술 설명서, 책들에서 반복적으로 언급될 만큼 매우 유명한 법칙이다. 그런데 다양한 버전이 나와있고, 조금씩 다르게 해석되는 경우가 많다. 그리고 실제로 무어 본인은 ‘무어의 법칙’이라는 말을 직접적으로 한 적은 없다. 이 표현은 후대 사람들이 그의 관찰과 예측을 정리하면서 붙인 이름이라고 할 수 있다.
무어가 무어의 법칙과 관련하여 가장 먼저 보이는 언급한 것은 1965년도이다. 그 해에 고든 무어는 미국 전자공학회(IEEE)가 발간하는 기술 잡지인 Electronics Magazine에 한 편의 기고문을 쓰게 되는데 그 문장이 무어의 법칙의 시작이라고 봐도 과언이 아니다.아래는 그 영문 원문이고, 그 뜻을 해석해보면 다음과 같다.
“The number of components per integrated circuit had doubled every year.” – 직접회로(집적회로)에 집적되는 컴포넌트의 수가 매년 2배씩 증가하고 있다.
즉, 해마다 회로 하나에 담을 수 있는 소자의 수가 기하급수적으로 늘어나고 있다는 것이다. 이게 바로 1965년도에 고든 무어가 했던 이야기다. 그리고 그로부터 10년 뒤인 1975년도에는 조금 수정한 내용으로 다시 이야기 한다. 이번에는 컴포넌트 수가 매년 두 배씩 증가하는 것이 아니라, 2년마다 집적도가 2배씩 올라간다고 말한 것이다. 이처럼 무어는 현실적인 기술 발전 속도를 반영해서 예측 주기를 조정했다. 그리고 이 예측은 이후 수십 년 동안 반도체 산업의 기술 로드맵으로 자리잡게 되었고, 실제로 반도체 제조사들은 이 법칙을 기준으로 기술 개발을 진행해 왔다고 해도 과언이 아니다.
그리고 우리가 가장 잘 알고 있는 무어의 법칙이 바로 이것이다. 물론 2년마다 두 배라고 알고 있는 사람들도 많을 것 같지만, 사람들 사이에서는 또 다른 버전도 널리 퍼져 있다. 그중 가장 많이 알려진 것은 인텔의 중역이었던 고든 무어가 1975년에 이야기한, 컴퓨터 칩의 성능은 대략 18개월마다 두 배가 된다는 이야기다. 여기서 언급된 ‘성능’이라는 개념은 단순히 컴포넌트의 수나 집적도만을 의미하는 것이 아니라, 연산 속도, 전력 효율, 발열 관리 등 다양한 요소를 종합한 개념으로 받아들여졌다.
그래서 무어의 법칙은 사람들마다 다르게 이해하고 있는 경우가 많다. 어떤 사람은 컴퓨터 칩의 성능이 18개월마다 두 배가 된다고 알고 있고, 또 어떤 사람은 2년마다 집적도가 두 배로 늘어난다고 알고 있다. 또 어떤 경우에는 이 두 가지를 혼합해서, 18개월 또는 2년마다 두 배의 성능 발전이 있다고 생각하는 경우도 많다. 이는 후대에 다양한 해석과 적용을 통해 무어의 법칙이 조금씩 변형되어온 결과라고 할 수 있다.
아무튼 고든 무어가 이야기한 내용과, 그 후에 데이비드 하우스(David House)가 보완해서 이야기한 핵심은, 결국 컴퓨터 칩의 성능과 집적도는 일정 기간 동안 약 두 배씩 증가한다는 것이다.
영원할 것 같던 무어의 법칙도 2000년대 초반을 기점으로 변화의 조짐을 보이기 시작한다. 당시만 해도 인텔을 비롯한 CPU 제조사들은 클럭 수, 즉 초당 연산 처리 속도를 계속해서 끌어올리는 방식으로 성능 향상을 이어가고 있었다. 클럭 수가 올라간다는 것은 그만큼 프로세서가 더 많은 연산을 단위 시간 안에 처리할 수 있다는 뜻이기 때문에, 당연히 성능이 향상된다는 의미였다. 그래서 많은 사람들은 이 속도가 계속 올라갈 것이라고 생각했고, 실제로도 그렇게 되어왔다. 그런데 집적도가 계속해서 올라가고, 공정이 작은 단위에 까지 이르다 보니 설계상 새로운 문제가 발생하게 된다.
가장 대표적인 것이 바로 발열 문제다. 회로가 너무 작아지고 빽빽하게 들어차다 보니, 전류가 흐를 때 발생하는 열을 효율적으로 분산시키기가 어려워진 것이다. 또한 소자의 크기가 원자 단위에 가까워지면서, 양자역학적인 현상들—예를 들어 전자의 터널링 현상이나 누설 전류 같은 문제가 회로 설계에 직접적인 영향을 미치기 시작한다. 이러한 물리적 한계에 도달하면서, 무작정 클럭 속도를 높이는 전략은 더 이상 효과적이지 않게 되었다. 결국 2010년 전후로는, CPU의 클럭 속도가 거의 더 이상 증가하지 않게 된다.
Free lunch is over
그리고 이때부터 새로운 방식의 CPU 설계 패러다임이 등장하게 된다. 바로 ‘코어’라는 개념이다. 이전에는 하나의 코어만 있었던 CPU에, 연산 유닛을 여러 개 넣어서 동시에 여러 작업을 처리할 수 있게 만든 것이다. 처음에는 듀얼 코어 CPU가 등장했고, 이어서 쿼드 코어, 그리고 지금은 16개 이상의 코어가 들어간 고성능 CPU들도 흔하게 판매되고 있다. 이러한 흐름은 무어의 법칙이 사실상 멈추었다는 신호로 받아들여졌다. 예전처럼 단일 코어의 성능이 기하급수적으로 향상되던 시대는 끝나버린 것이다. 그리고 무어의 법칙이 멈추면서, 소프트웨어의 성능이 자연스럽게 향상되던 흐름도 함께 멈추게 된다. 이전에는 하드웨어 성능이 올라가면, 프로그래머가 특별히 코드 최적화를 하지 않아도 프로그램이 자연스럽게 빨라졌지만, 이제는 더 이상 그런 일이 일어나지 않게 된 것이다.
이 현상에 대해 당시 유명한 기술 잡지였던 《Dr. Dobb’s Journal》에서 허브 슈터(Herb Sutter)가 ‘Free Lunch is Over’로 표현하였다. 즉 CPU의 발전 덕분에 자동으로 얻던 성능 향상의 시대가 끝났다는 의미를 담고 있다. 이제부터는 프로그래머가 코드를 병렬화하지 않으면 성능을 높일 수 없다는 현실을 말한 것이다. 즉, CPU의 코어 수가 늘어나는 시대에는 프로그램의 구조도 이에 맞춰 바뀌어야 한다는 말이다. 이전까지는 순차적인 구조의 프로그래밍도 CPU 클럭이 증가하면서 자연스럽게 빨라졌지만, 멀티코어(Multi-core) 또는 매니코어(Many-core) 프로그래밍을 하지 않으면 소프트웨어의 성능이 더 이상 개선되지 않는다는 사실이 명확해진 것이다.
보다 자세한 내용은 링크(http://www.gotw.ca/publications/concurrency-ddj.htm)에서 확인할 수 있다. 그리고 아래의 그래프는 바로 그때 이 설명과 함께 사용된 그래프이다. 이 그래프를 보면, 무어의 법칙이 완전히 멈췄다고 보긴 어렵지만, 이전과는 전혀 다른 방향으로 전환되었음을 분명히 알 수 있다.
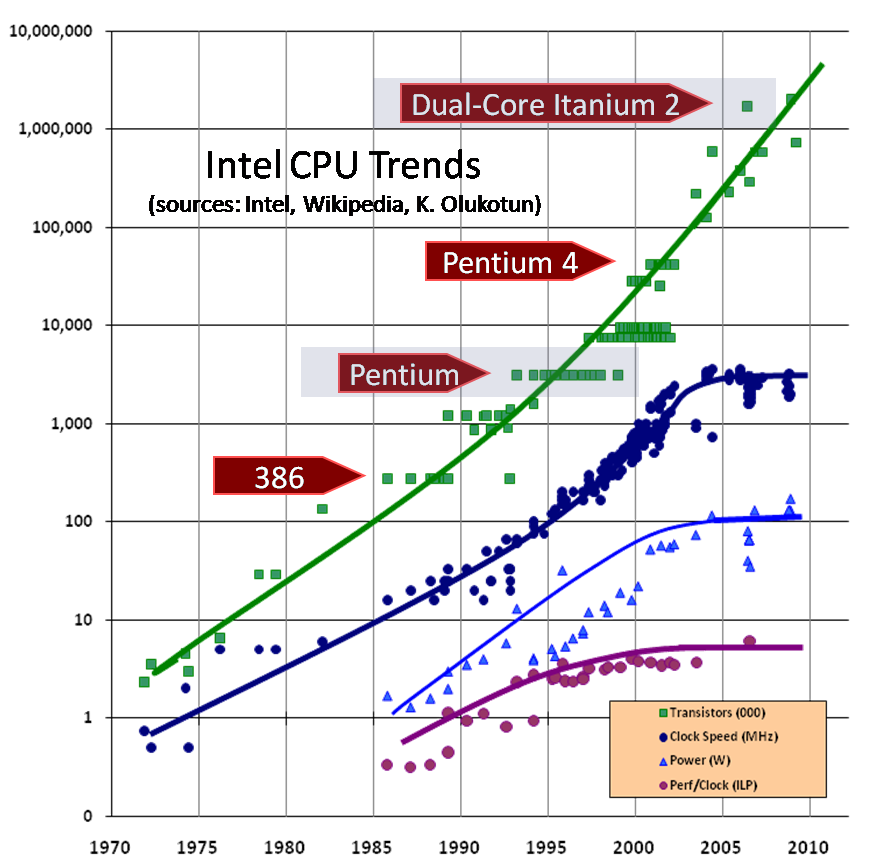
Source: http://www.gotw.ca/publications/concurrency-ddj.htm
그래프를 보면 트랜지스터 수는 여전히 꾸준히 증가하고 있다는 것을 확인할 수 있다. 이는 집적도가 증가하고 것이 아니라, 여러 개의 코어를 추가함으로써 전체적인 트랜지스터 수가 증가한 것임을 의미한다. 즉, 하나의 강력한 코어 대신, 여러 개의 효율적인 코어를 병렬로 동작시키는 방식으로 발전 방향이 바뀐 것이다. 또한 중요한 점은, 전력 소비(Power Consumption)도 예전처럼 급격히 늘어나지 않고 일정 수준을 유지하고 있다는 것이다. 이는 하나의 코어에 과도한 연산을 집중시키지 않고, 여러 개의 코어에 분산시켜 부하를 나누었기 때문이다. 그래서 코어 수는 늘어나고 있지만, 파워는 일정 수준에서 머무르게 되었고, 코어의 동작 속도(클럭) 역시 비슷한 수준에 머무르게 된 것이다.
무엇이 필요한가?
좋아, 지금 이 문단도 앞에서 설정한 스타일 그대로—문장을 생략하거나 축약하지 않고, 문장의 흐름과 의미를 확장하며 블로그에 적합한 형태로 자연스럽게 다듬어서 아래와 같이 정리해봤어:
멀티코어 시대, 그리고 GPU의 역할
CPU가 더 이상 클럭 속도를 높일 수 없게 되면서(물론 조금씩 속도가 늘고는 있다.) 더 많은 연산을 처리하기 위해 코어를 여러 개로 나누는 전략이 핵심적인 해결책으로 떠오르게 된 것이다. 그리고 이런 흐름은 자연스럽게 GPU로 이어지게 된다. 왜냐하면, GPU라는 것은 수많은 코어들의 집합체이기 때문이다. 말하자면, GPU는 대규모 멀티코어(Many-core)의 대표적인 구현체라고 볼 수 있다. CPU가 4개, 8개, 16개의 코어를 가진다면, GPU는 수백, 수천 개의 연산 유닛을 병렬로 연결해 한 번에 수많은 작업을 처리할 수 있도록 설계되어 있다.
하지만 이번 편에서는 GPU 자체의 구조나 멀티코어, 메니코어의 기술적인 세부사항보다는, 이러한 변화에 대응하기 위해 거시적인 수준에서 무엇이 필요한지, 즉 무어의 법칙 이후의 시대를 우리는 어떻게 준비하고 받아들여야 하는가에 대해 먼저 이야기해보려 한다. 다음에 소개할 그림은 C. E. Leiserson 외 연구자들이 사이언스(Science)지에 발표한 논문[1]에서 발췌한 것이다. 이 논문은 무어의 법칙이 사실상 끝난 이후, 우리는 어떤 방식으로 기술 발전을 이어가야 하는가라는 질문에 대한 대답을 하고 있다.
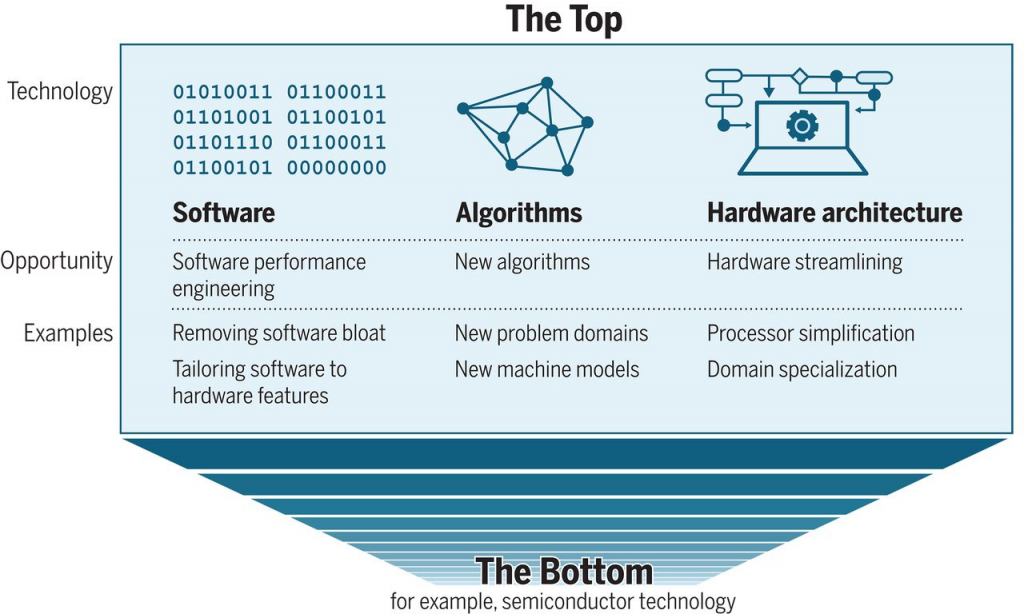
무어의 법칙은 2010년도 이전부터 이미 한계에 도달했고, 그에 대응하기 위한 다양한 기술적 방법론과 전략들이 제시되고 실행되어 왔다. 그렇기 때문에 2020년에 다시 무어의 법칙 이후를 논하는 것이 다소 뒤늦은 논의로 보일 수도 있다. 하지만 이 논문이 중요한 이유는, 이미 실전에서 사용되고 있던 다양한 접근법들을 정리하고 체계화했다는 점이다. 따라서 어떤 면에서는 새로운 내용을 제시했다기보다는, 기존의 흐름을 하나의 프레임워크로 깔끔하게 정리해주었다는 데에서 의의가 있다고 볼 수 있다. 그리고 바로 그 점이 이 논문을 소개하고 싶은 이유이기도 하다.
그림에는 무어의 법칙이 멈춘 이후 어떤 요소들이 중요해졌는지가 구조적으로 정리되어 있다. 크게 보면 세 가지 축이 중심에 자리잡고 있다: 소프트웨어, 하드웨어 아키텍처, 그리고 알고리즘이다. 먼저, 하드웨어 아키텍처를 보면 이는 GPU뿐만 아니라, 최근 주목받고 있는 MPU(Matrix Processing Unit), NPU(Neural Processing Unit) 등의 새로운 연산 처리 유닛들도 포함한다. 이 아키텍처는 단순히 코어 수를 늘리는 것을 넘어서, 네트워크, 메모리, 스토리지 등 시스템 전반의 구조적인 설계를 포함하는 넓은 개념이다. 즉, 단일 장치의 성능 향상이 아니라, 하드웨어 전체의 조화와 효율을 고려하는 설계 전략이 중요해졌다는 의미다.
그리고 다음으로 소프트웨어다. 이런 새로운 하드웨어 구조를 제대로 활용하려면, 그에 최적화된 소프트웨어가 반드시 필요하다. 예를 들어, NVIDIA의 CUDA, 그리고 Google의 TensorFlow, Facebook이 주도하는 PyTorch 같은 프레임워크들이 있다. 이들은 단순한 라이브러리가 아니라, 멀티코어, 메니코어 환경을 적극 활용할 수 있도록 구성된 소프트웨어 플랫폼이다. 이런 플랫폼이 있어야만, 병렬처리가 가능한 알고리즘들이 제 성능을 발휘할 수 있다. 마지막으로 그림의 중앙에는 알고리즘이 있다. 결국 하드웨어가 아무리 좋아지고, 소프트웨어 플랫폼이 아무리 정교해져도, 그 위에서 돌아가는 알고리즘이 병렬 처리에 적합하지 않으면 전체 시스템의 성능은 제약을 받게 된다.
현재 우리가 주목하고 있는 딥러닝 알고리즘들을 예로 들어보자. 딥러닝 학습은 기본적으로 수많은 데이터와 매개변수를 반복적으로 계산하는 구조로 되어 있다. 이런 구조는 병렬화에 매우 적합하며, 그래서 여러 개의 코어에 학습 작업을 분산시키는 병렬 처리 구조로 설계된다. 예를 들어, TensorFlow나 PyTorch 같은 프레임워크는 이러한 병렬 학습을 지원하는 기능을 이미 갖추고 있고, 더 나아가서 NVIDIA의 NeMo, Megatron 같은 고성능 딥러닝 프레임워크들은 초대규모 모델 학습을 위해 분산 학습과 병렬 연산을 기반으로 한 고성능 시스템까지 제공하고 있다.
이처럼, 무어의 법칙이 멈춘 이후에도 기술 발전은 계속되고 있으며, 그 방향은 하드웨어 아키텍처의 혁신, 알고리즘의 병렬 처리 구조화, 그리고 그 사이를 이어주는 플랫폼 소프트웨어의 진화가 핵심이라는 사실이 점점 더 분명해지고 있다.
서두를 마치며
세상에 존재하는 어떤 물건이나 이론도, 갑자기 하늘에서 뚝 떨어지듯 등장하는 일은 없다. 지금 우리가 보는 많은 결과들은 오랜 시간에 걸친 고민과 시도, 그리고 소프트웨어와 하드웨어의 변화에 맞춘 진화의 결과물이다. 즉, 기술의 발전은 결코 우연에 의해 이루어지는 것이 아니라, 수많은 작은 요소들이 서로 유기적으로 연결되면서 거대한 변화를 만들어낸 것이다.
하지만 사람들은 종종 그 원인과 과정, 시간의 축적을 보지 않고 결과만을 주목하는 경향이 있다. 그런 점에서 보면, 지금 우리가 눈앞에서 보고 있는 GPU의 위상 역시 단순한 기술 하나의 성공이 아니라, 시대 흐름과 수많은 기술적 조건들이 맞물린 복합적인 결과라는 점에서 이해되어야 마땅하다.
그래서 이 시리즈에서는 단순히 결과를 보여주는 방식보다는, 귀납적 접근이 아닌 연역적 방식으로, 그 결과에 이르게 된 배경과 과정을 먼저 풀어가고자 한다. 즉, 지금 우리가 보고 있는 AI 시대의 핵심 기술, GPU가 왜, 어떻게 그 위치에 오르게 되었는지를 앞으로 단계적으로 보여줄 것이다. 이제 막 첫걸음을 뗀 이 시리즈가 앞으로 어떤 흥미로운 이야기들을 풀어나갈지 기대해도 좋다. GPU가 AI를 바꾸었고, 세상을 바꾸고 있다는 사실, 그 이면에 담긴 수많은 이야기들을 함께 따라가보자.
전에 정리 해 놓은 GPU 포스트들은 이 시리즈에 맞게 수정 되거나 재작성 될 예정이다.
[1] Leiserson, C.E. et al. “There’s Plenty of Room at the Top: What Will Drive Computer Performance After Moore’s Law?” Science, 2020.