들어 가며..
인공지능에 대한 개발 관심도와 기술이 나날이 발전하고 있습니다. 조금 더 빠른 속도와 높은 정확도를 얻기 위한 무한 경쟁이 쉬지 않고 이루어 지고 있죠.
GPGPU사용이 당연시 되는 Deep Learning 환경에서 탈피하고자 구글이나 그래프코어 같은 회사에서 TPU, IPU같은 새로운 하드웨어를 개발하고 관련된 SW들도 함께 내 놓고 있습니다.

GPU를 사용하면 또는 다양한 XPU를 사용하면 딥러닝이 빠르다고 알고 있지만 XPU의 어떤 기술 때문에 딥러닝이 빨리 지는지는 잘 모르는게 현실입니다.
이번 포스트에서는 GPU, TPU, IPU들을 합쳐서 부르는 XPU가 어떤 기술적인 관점에서 Deep Learning을 빠르게 할 수 있는지와 각각이 어떤 특징을 가지고 있는지 확인해 보도록 하겠습니다.
그냥 좋은 GPU 계속 사서 갈아 넣으면 좋은데 구지 알아야 하나? 라고 생각하실 수 있지만 사실 구형 GPU라도 100% 활용을 못하고 있는게 사실이기 때문에 NVIDIA P, V, A 계열이 뭐가 좋아 지는지, 왜 사야 하는지를 알게 되면 본인들의 Workload에 적합한 투자인지 아닌지 알수 있게 되는거죠.
Deep Learning에서 Hardware Accelerator 역할
먼저 XPU가 어떻게 Deep Learning(앞으로 DL로 표기)에서 학습 속도를 빠르게 할 수 있는지부터 정리해 보도록 하겠습니다. XPU(GPU, TPU, NPU, IPU)를 주 CPU 연산이 아닌 보조적인 연산이라는 의미에서 Hardware Accelerator라고 부릅니다. 용어에 대해서 약간 삼천포로 빠져서 한가지만 덧붙이자면, 지금은 약간 시들해 졌지만 인텔에서 x486급의 CPU를 집적해서 만든 Intel Xeon Phi라는 Hardware Accelerator가 있었습니다. 인텔에서는 여러개의 프로세스가 메인 프로세스와 함께 연산된다고 하여 co-processor라는 단어를 사용하기도 하였습니다.
XPU가 Deep Learning에서 속도를 빠르게 하는 것은 DL 안에서 수업이 반복되는 Linear Algebra(선형 대수) 연산의 속도를 빠르게 하는 것입니다. 또는 DL 연산 자체를 병렬화 또는 최적화 하여 속도를 높이기도 하죠.
Linear Algebra는 DL 연산의 대부분을 차지 하는 중요한 Operation 들입니다. 대표적인 연산은 아래와 같습니다.
- Transpose (AT)
- Matrix Product (AB)
- Element-wise Product or Hadamard Product (A⊙B)
- Matrix Inverse (A-1)
- Norm
- Eigen Decomposition (Av=λv)
- Vector reductions
- Gradients and Jacobians
- determinant ( det(A) )
Gradients와 Jacobians는 기본적인 Linear Algebra는 아니지만 미분을 위해서 많이 사용되는 연산입니다. XPU는 위의 열거한 연산들을 각자의 방식에 맞게 빠르게 연산하는 방법을 하드웨어 적으로 구현한 것입니다.
Linear Algebra의 연산을 어떻게 빠르게 만들 수 있을까요? XPU별로 약간씩 차이가 있지만 연산을 빠르게 만드는 기술은 아래처럼 분류 할 수 있습니다.
- SIMD (Single Instruction Multiple Data),
- MIMD (Multiple Instructions Multiple Data)
- Systolic Architectures (Systolic Operation)
- Memory Locality Optimization
이외에도 많은 테크닉들이 있지만 대표적으로 이 4가지가 가장 많이 사용됩니다. 특히 SIMD는 Hardware Accelerator가 제공하는 성능 향상의 Key 입니다. 하나의 명령어를 여러개의 데이터에 적용하는 것입니다. Matrix 연산을 생각해 보면 행과 열의 곱과 합을 반복 합니다. 하나의 명령어에 데이터만 변경이 되는거죠. 이 것을 한번에 여러 행과 열의 계산을 한 번에 하는 것입니다. 빠르겠죠? 이런 병렬 연산을 어떻게 효과적으로 처리 하느냐가 XPU 하드웨어 내부적으로 하고 있는 일입니다.
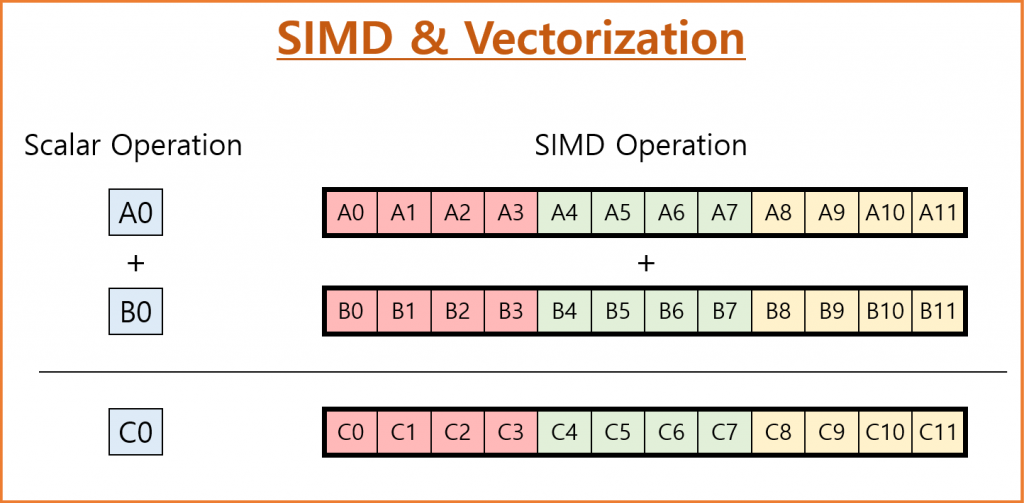
※ GPGPU에서는 SIMD 대시 SIMT(Single Instruction Multiple Threads) 라는 단어를 사용합니다. Hardware Thread에 동일한 연산을 동시에 수행하는 것을 말합니다. SIMD와 유사한 개념이기 대문에 SIMD로 통칭 하도록 하겠습니다.FMA(FFMA), Systolic Architecture 자세히 알아 보기
SIMD, MIMD와 Memory Locality Optimization외에 한가지 더 살펴 볼까요? Matrix Product을 생각해 보면 행과 열의 각 엘리먼트들의 곱을 합하는 과정입니다. 자세히 살펴 볼까요?
ax(행과 열 각 엘리먼트 각각의 곱) + b(결과 누적치, 처음은 0)
명령어가 2가지이죠. 곱과 합. 이 이야기는 명령어 cycle이 2번이라는 이야기 입니다. 그런데 이 과정이 엄청 많이 반복됩니다. 반복이 되니 이것을 빠르게 하기 위한 연산이 나왔습니다.
FMA(fused multiply-add) : ax+b를 1 cycle에 연산하는 것
그리고 이것을 부동소수점에도 적용을 하면
FFMA(floating point fused multiply-add)
FFMA는 XPU에서 많이 사용되는 연산들입니다. SIMD를 기본으로 하면서도 연산의 횟수를 줄이는 방법이죠. 그럼 CPU는 없느냐? 그렇지 않습니다. 여러분이 사용하시는 CPU에도 병렬처리를 위한 연산들이 들어 있습니다. AVX2라고 불리는 명령어 Set이 하스웰 아키텍쳐 부터 지원이 됩니다. 하지만 CPU 자체는 ALU의 숫자가 XPU에 비해서 현저히 적기 때문에 큰 효율을 못 내고 있죠. 하지만 서버용 CPU인 Xeon의 경우 수십개의 CPU Core가 존재 하기 때문에 효과가 꽤 있습니다. 때문에 서버에서는 CPU에서도 병렬처리를 통해서 DL 전처리를 하기도 합니다.
FMA, FFMA 역시 Hardware Accelerator가 지원하는 중요한 연산 중 하나 입니다.
Systolic Architecture는 GPGPU보다는 TPU, IPU에서 많이 사용되는 방식입니다. 병렬 처리에서 동시 처리 보다 중요한 부분이 데이터가 계산이 필요한 곳에 가장 알맞은 시기에 도착해 있는 것입니다. 이를 위해서 Pre-Patch를 할 수도 있고, Pipiline을 잘 설계할 수 도 있습니다. 하지만 Host에서 Accelerator로 데이터 복사가 빈번할 경우 성능 저하가 발생할 수 있습니다. Systolic Architecture는 데이터 연산시 데이터 복사가 최소화 되도록 하는 방법입니다. 이는 PE(Processing Element)가 독립된 NPU 계열이 처리가 유리하기 때문에 GPGPU보다 NPU 계열에서 많이 사용 되는 방법입니다. 이를 통해서 Memory Locality를 향상할 수 있습니다. 구글의 TPU가 사용하는 대표적인 방법입니다.
위의 그림은 Matrix Multiply를 그림으로 나타낸 그림 입니다. 그림을 통해서 Systolic에 대해서 알아 보겠습니다. A Matrix와 B Matrix를 곱해서 C Marix에 저장한다고 할 때, A Matrix A00이 연산에 사용 되는 C Matrix 위치에 빨간색 동그라미를 표시 하였습니다. 같은 방법으로 B Matrix의 B00을 파란색 동그라미로 표시 하였습니다.
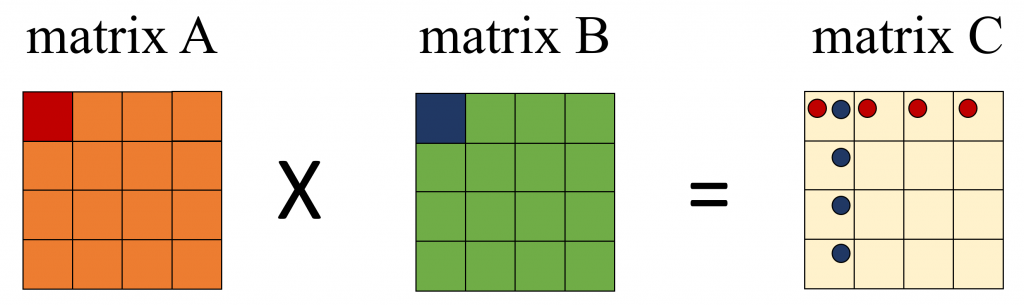
C00은 A00, A01, A02, A03각각과 B00, B10, B20, B30각각을 곱한 값을 더한 결과 입니다. C01은 A00, A01, A02, A03 각각과 B10, B11, B12, B13각각을 곱한 값을 더한 결과 입니다. 이런 식으로 생각해 보면 A00는 C00, C01, C02, C03 연산에 사용됩니다. B00는 C00, C10, C20, C30 를 계산하는 연산에 사용됩니다. A00, B00등을 계산시 마다 Offloading을 하면 아주 많은 Cost가 발생할 것 입니다. Systolic은 혈관에 혈액이 흐르듯이 이 A00, B00를 PE들이 연산할 수 있도록 첫번째 연산시에만 Offloading을 하고 PE간 데이터를 이동하면서 사용하는 방법입니다. 당연히 PE에 Local 메모리가 존재 해야만 합니다. 많은 NPU들이 Local Cache, Local Memoery를 가지고 있기 때문에 Offloading의 Overhead를 극복할 수 있는 것입니다. 아래 그림이 보시면 이해가 되실 겁니다. C Matrix의 각 엘리먼트의 연산을 1개의 PE가 담당한다고 가정합니다.
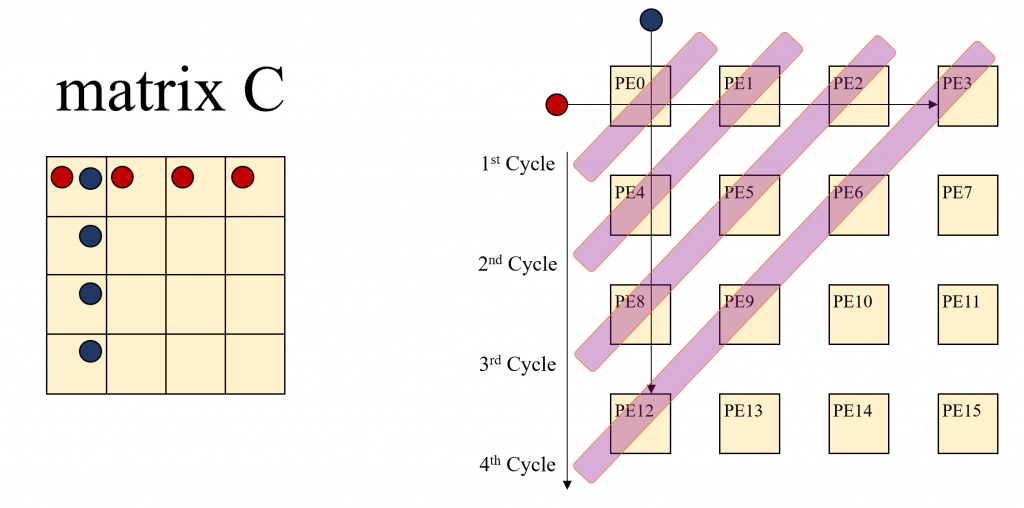
Systolic Achitecture에서는 앞서 설명한 것처럼 A00, B00가 가장 먼저 offloading 된 후에 곱해진 후에 C00에 저장됩니다. A00, B00는 다음 연산을 위해 각각 C01, C10으로 이동합니다. 그리고 다음 연산을 위해서 데이터가 추가로 offloading 됩니다. 이때는 C00 의 전체 연산의 다음 계산을 위해서 A01, B10이 Offloading되고 C01에서 A00와 계산될 B01이 C10에서 B00와 계산될 A10 이 Offloading 됩니다. 이런 연산을 수행하면 연산의 순서가 왼쪽 상단에서 부터 오른쪽 하단으로 연산이 확산되는 형태를 볼 수 있습니다. 새롭게 Offloading된 데이터는 A Matrix 값은 Row Index를 유지하면서 오른쪽으로 B Matrix으 값은 Column Index를 유지 하면서 아랫쪽으로 이동하면서 연산에 사용됩니다.
여기까지 XPU들이 DL을 빠르게 하기 위한 전략을 간단하게 정리해 보았습니다. 이제부터 XPU를 하나씩 살펴 보도록 하겠습니다.
연산 가속을 위한 Hardware Accelerator
XPU 별 특징
앞에서 이야기 한 SIMD, MIMD, Systolic Architecture, FMA, Memory Locality등은 XPU 모두가 활용하고 있는 기술들입니다. 모두가 동일한 방법으로 연산을 한다면 연산의 속도(Latency)와 연산의 용량(Throughput)이 XPU 선택의 주요 고려 사항이 될 것입니다. 당연히 가격 대비 성능도 고려되겠지요. 하지만 XPU들은 각기 다른 저마다의 특징이 있습니다. GPGPU, TPU, IPU 세가지 Hardware Accelerator에 대해서 간략히 정리해 보았습니다. 개략적인 내용을 살펴 본 후에 하나씩 자세히 살펴 볼까요?
- NVIDIA의 GPGPU (General-Purpose computing on Graphics Processing Unit)
Hardware accelerator에서 가장 많이 알려진 가속기는 NVIDIA의 Tesla입니다. (General Purpose GPU의 Tesla 계열로 한정) Tesla Pascal 계열 까지는 Core의 고집적도화, 공유 메모리 향상 및 메모리 버스 속도 향상으로 속도를 향상 시켰습니다. Volta 계열 부터는 Tensor연산을 위한 Tensor core를 추가 하여 Tensor 연산 자체를 병렬화 하였습니다. 이로 인해서 ML 학습, 추론의 전체 속도를 향상 시켰습니다. Volta 계열에서는 FP16만을 지원하지만 Ampere 계열 부터는 FP64, TF32, bfloat16, FP16, INT8, INT4, INT1을 지원하여 다양한 데이터 타입을 지원하여 여러 경우의 연산에서 성능 속도를 향상 시켰습니다. - Google의 TPU (Tensor Processing Unit)
TPU는 Tensor를 하드웨어적으로 처리를 하는 보조 연산 장치를 말합니다. TPU는 Linear Algebra 연산을 빠르게 구현한 것 뿐만 아니라 inference(추론)에서 32 bits floating point를 사용하지 않고 8 bits int를 사용하여 2015년 Nvidia의 K Series GPU보다 10~30배의 효과 적인 성능을 구현 하였습니다. NPU 계열의 TPU는 Systolic Architecture를 도입하여 Tensor(Matrix) 연산의 효율을 극대화 하여 TPU v2, 3에서는 inference뿐 아니라 training에서도 높은 성능을 보여주고 있습니다. - GraphCore의 IPU (Intelligence Processing Unit)
Matrix 연산을 위한 Hardware accelerator는 매우 다양합니다. 그 중에서 GraphCore의 IPU를 예로 든 이유는 2가지 입니다. 첫 번째 이유는 구조나 원리에 대한 정보가 많이 있어서 입니다.(설명을 해야 하므로) 두 번째 이유는 IPU가 가지고 있는 구조적 특징 때문입니다. IPU는 GPGPU처럼 SIMD 처리를 위한 ALU가 고집적 되어 있는 구조입니다. 그리고 GPGPU와 다르게 Control Flow/Prediction과 Local Memory(SRAM)를 가지고 있습니다. 이를 활용하여 MIMD가 가능하도록 하였고 Memory Locality를 극대화 하여 계산 속도를 최대화 하였습니다.

Zinskauf / CC BY-SA (https://creativecommons.org/licenses/by-sa/4.0)

3가지 모두 Linear Algebra를 빠르게 하기 위해서 각기 다른 전략을 구사하고 있습니다. 제조사별로 본인들의 장치가 가장 뛰어나다고 주장은 하지만 저의 생각은 각각의 특성을 이해하고 이를 활용할 수 있는 방법이 중요한 것이지 우열을 가르는 것은 의미가 없다고 생각합니다. 어차피 Hardware라는 것은 시간이 지나면 좋아지기 때문에 오늘의 1등이 영원한 1등은 아니기 때문입니다.
다음 포스트에서는 3가지 Hardware Accelerator이 가지고 있는 특징에 대해서 자세히 알아 보도록 하겠습니다. GPGPU, TPU, IPU의 동작 방식에 대해서 알아 보면서 추가적인 Hardware Accelerator인 Cerebras 시스템과 Habana Lab 제품에 대해서도 간단하게 알아 보겠습니다.